数据库1, 数据库的安装和配置1.1 数据库的概念数据库的定义: 了解数据库的历史: 了解1.2 数据库的分类数据库分类一些数据库: 了解1.3 数据库的安装1.4 数据库构成客户端和服务器MySQL的内部数据组织方式2, SQL语法2.1 SQL语言2.2 SQL的基本操作2.2.1 登录数据库2.2.2 库操作查看数据库创建数据库删除数据库修改数据库选择数据库2.2.3 表操作常见的数据类型(1) 整数(2) 浮点数(3) 日期(4) 字符串查看表创建表主键和自增问题修改表删除表2.2.4 数据操作添加数据查询数据修改数据删除数据2.3 特殊关键字2.3.1 Where2.3.2 Distinct2.3.3 Limit 2.3.4 As2.3.5 Order By2.3.6 Group By2.3.7 聚合函数2.4 SQL执行顺序2.5 数据完整性2.5.1 实体完整性2.5.2 域完整性2.5.3 参照完整性3, SQL和多表问题3.1 多表设计/多表理论3.1.1 一对一3.1.2 一对多3.1.3 多对多 3.1.4 数据库设计范式第一范式: 原子性第二范式: 唯一性第三范式: 不冗余3.2 多表查询3.2.1 链接/连接查询交叉链接自然连接内连接外连接: 左右外连接自连接3.2.2 子查询3.2.3 联合查询4, 数据库备份和恢复4.1 命令行操4.2 图形化界面5, 上课sql7月2号的sql7月3号是sql
数据库
1, 数据库的安装和配置
1.1 数据库的概念
数据库的定义: 了解
1, Database:A database is an organized collection of data,stored and accessed electronically.
2, 数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
3, 数据库(Database)是一种结构化信息或数据的有组织的集合。
4, 在现实中,
数据以及[数据库管理系统 (DBMS)](Database Management System)一起被称为数据库系统,通常简称为数据库。
数据库的历史: 了解
自 20 世纪 60 年代初诞生至今,数据库已经发生了翻天覆地的变化。最初,人们使用分层数据库(树形模型/一对多)和网络数据库(图模型/多对多)这样的导航数据库来存储和操作数据。这些早期系统是很简单的,同时也缺乏灵活性。
20 世纪 80 年代,关系数据库开始兴起.
20 世纪 90 年代,面向对象的数据库开始成为主流。
最近,随着互联网的快速发展,为了更快速地处理非结构化数据,NoSQL 数据库应运而生。
1.2 数据库的分类
数据库分类


关系型数据库:关系数据库在 20 世纪 80 年代成为主流。关系数据库中的
数据项被组织为一系列具有列和行的表。关系数据库为访问结构化信息提供了有效和灵活的方法.非关系型数据库:又被称为NoSQL数据库,它支持存储和操作
非结构化及半结构化数据。而且随着 Web 应用的日益普及和复杂化,NoSQL 数据库得到了越来越广泛的应用.等...
注: 区别 注意
SQL标准/SQL语言: 1986年定义了一个SQL标准: SQL标准语言 (SQL语言操作数据, 是以数据和数据之前的关系去操作数据的)
SQL语句: select * from user; 从user表中查出所有信息
关系型数据库和非关系型数据库, 虽然区别很多, 但是
最本质的区别是: 关系型数据库以数据和数据之间存在的关系维护数据, 而非关系型数据库是指存储数据的时候数据和数据之前没有什么特定关系.大家要注意的是, 虽然数据库有种类的区别,但是这是一个无关孰优孰劣的问题(没有谁好谁差之分),主要取决于企业希望如何使用数据.从本质上讲, 他们都是用来存储数据的. (而对于我们一个Java后端开发来讲, 我们在实际工作中基本上是以关系型数据库为主, 非关系型数据库为辅的用法)
注: 关于NoSQL的SQL解释
SQL:结构化查询语言(Structured Query Language)简称SQL,是一种专门用来和数据库通信的标准语言,用于向数据库存取数据以及查询、更新和管理关系数据库系统. 每个
关系型数据库都支持SQL语言/SQL标准.
一些数据库: 了解
MySQL
是一个由瑞典MySQLAB公司开发,属于Oracle旗下产品。MySQL是最流行的关系型数据库管理系统之一
Oracle
又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小微机环境。它是一种高效率的、可靠性好的、适应高吞吐量的数据库方案.
SQLServer
SQLServer是由
微软公司开发的一种关系型据库管理系统,它已广泛用于电子商务、银行、保险、电力等行业。SQLServer提供了对XML和Internet标准的支持,具有强大的、灵活的、基于Web的应用程序管理功能。而且界面友好、易于操作,深受广大用户的喜爱,但它只能在Windows平台上运行(2017年开始支持Linux系统),并对操作系统的稳定性要求较高,因此很难处理日益增长的用户数量。
DB2数据库
DB2数据库是由IBM公司研制的一种关系型数据库管理系统,主要应用于OS/2、Windows等平台下,具有较好的可伸缩性,可支持从大型计算机到单用户环境。
DB2支持标准的SQL,并且提供了高层次的数据利用性、完整性、安全性和可恢复性,以及从小规模到大规模应用程序的执行能力,适合于海量数据的存储,但相对于其他数据库管理系统而言,DB2的操作比较复杂。
MariaDB
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,使用XtraDB来代替MySQL的InnoDB。 MariaDB由MySQL的创始人Michael Widenius主导开发,他早前曾以10亿美元的价格,将自己创建的公司MySQL AB卖给了SUN,此后,随着SUN被甲骨文收购,MySQL的所有权也落入Oracle的手中。MariaDB名称来自Michael Widenius的女儿Maria的名字。
MariaDB基于事务的Maria存储引擎,替换了MySQL的MyISAM存储引擎,它使用了Percona的 XtraDB,InnoDB的变体,分支的开发者希望提供访问即将到来的MySQL 5.4 InnoDB性能。这个版本还包括了 PrimeBase XT (PBXT) 和 FederatedX存储引擎。
PostgreSQL
是以加州大学伯克利分校计算机系开发的 Postgres 版本 4.2 为基础的对象关系型数据库管理系统(ORDBMS)。和MySQL一样是开源数据库。POSTGRES 领先的许多概念只是在非常迟的时候才出现在商业数据库中。
MongoDB数据库
MongoDB是由10gen公司开发的一个
介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似JSON的bjson格式,因此可以存储比较复杂的数据类型。Mongo数据库管理系统最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。不仅如此,它还是一个开源数据库,并且具有高性能、易部署、易使用、存储数据非常方便等特点。对于大数据量、高并发、弱事务的互联网应用,MongoDB完全可以满足Web2.0和移动互联网的数据存储需求。
Redis
Remote Dictionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。 Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
1.3 数据库的安装
1.数据库安装
安装数据库: 安装的是一个具有监听端口/分析SQL语句/存储数据/组织数据/响应数据为一体的数据库服务器
xxxxxxxxxx331// 更新包列表2sudo apt update3// 安装mysql4sudo apt install mysql-server mysql-client5// 安装客户端依赖包(编程需要)6sudo apt install libmysqlclient-dev7// 查看mysql状态8netstat -tap | grep mysql9// 设置账号密码相关的信息 (选项选Y)(密码级别选0)11sudo mysql_secure_installation12// 查看mysql状态14systemctl status mysql.service15// 也可用于查看mysql状态16sudo service mysql status17// 访问mysql19sudo mysql -u root -p20// 设置密码长度 (SHOW VARIABLES LIKE 'validate_password%';)22set global validate_password.length=6;23// 修改用户的认证方式和密码24alter user 'root'@'localhost' identified with mysql_native_password by '123456';25// 刷新26flush privileges;27// 退出mysql客户端28exit;29// 重启mysql31service mysql restart32//或者33systemctl restart mysql
2.客户端连接数据库
3.Navicat连接数据库
1.4 数据库构成
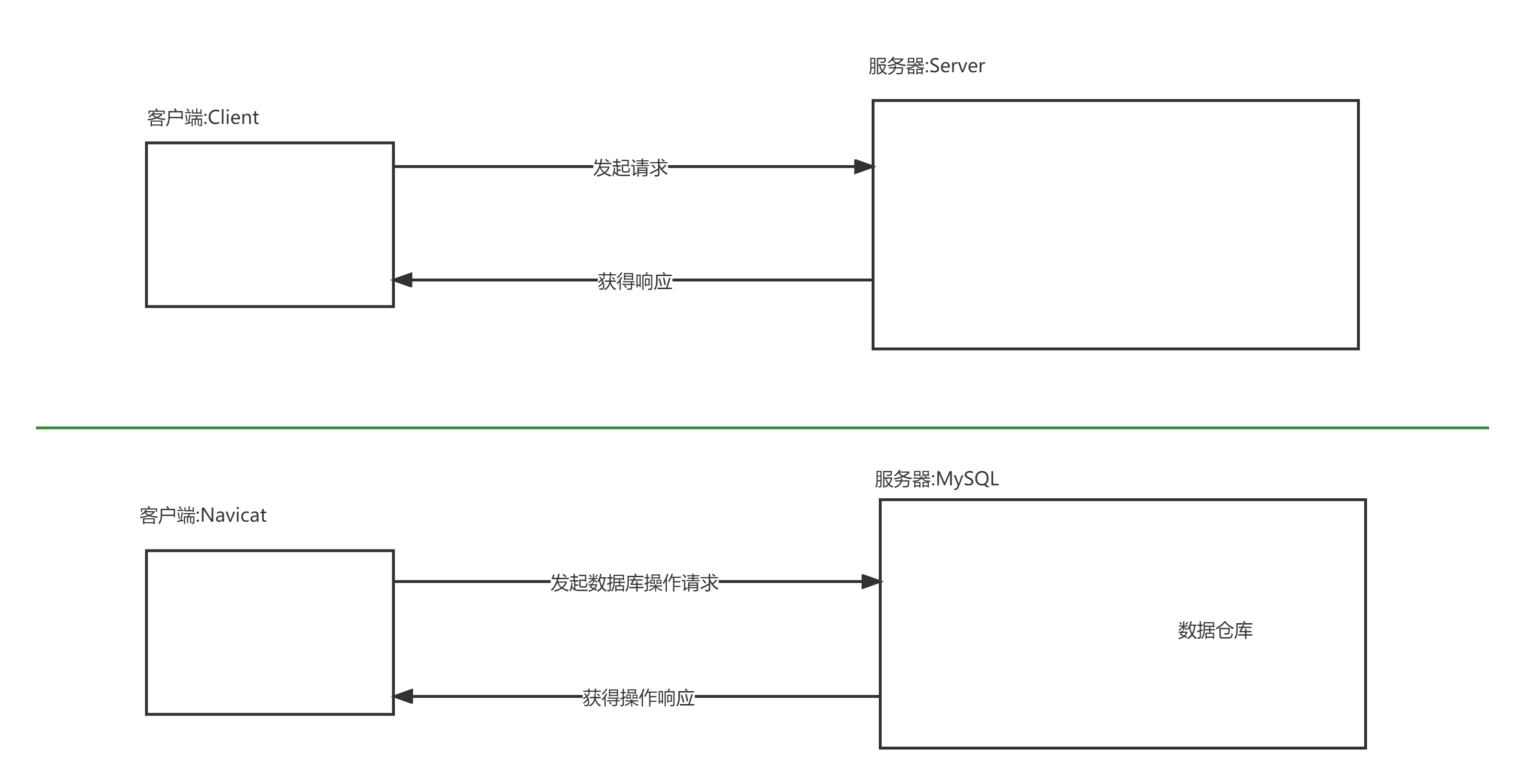
客户端和服务器
在互联网的网络交互和数据访问中,一般常见两种网络架构模式: B/S结构或者C/S结构.
B/S: Browser-Server即浏览器和服务器, 即通过浏览器和服务器发起网络交互的数据请求.
C/S: Client-Server即客户端和服务器, 即通过客户端和服务器发起网络交互的数据请求.
而我们上面安装的Navicat以及MySQL, 这两者的关系是一个标准的C/S结构.
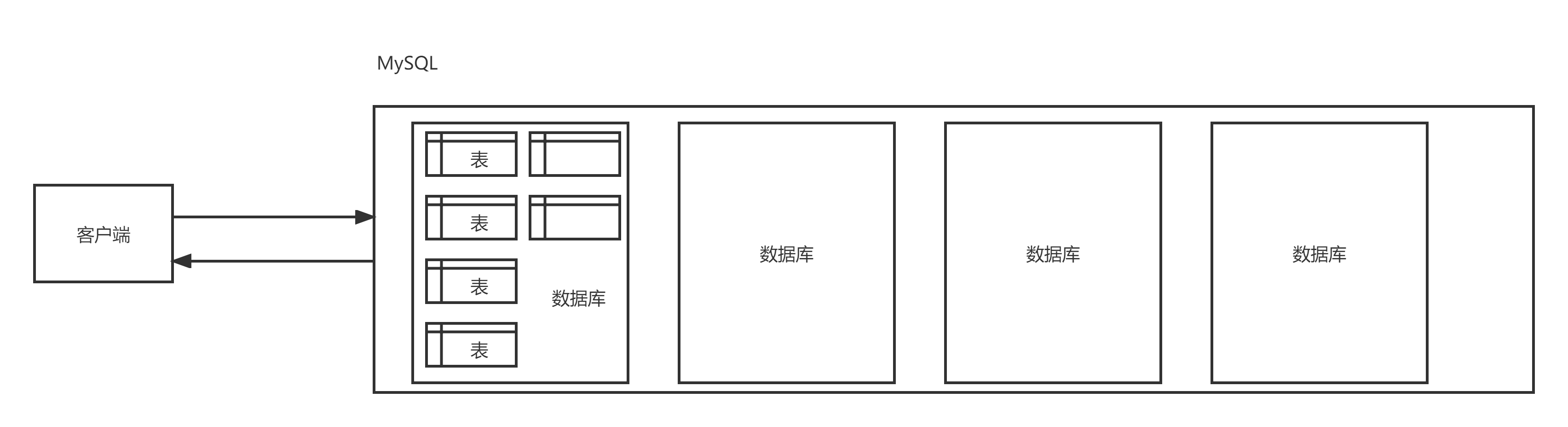
MySQL的内部数据组织方式
在MySQL中, 我们对数据的组织逻辑上是按照
库/表/数据这种三级结构组织的.数据库: 表示一份完整的数据仓库, 在这个数据仓库中分为多张不同的表.
表: 表示某种特定类型数据的的结构化清单, 里面包含多条数据.
数据: 表中数据的基本单元.
2, SQL语法
2.1 SQL语言
SQL语言
SQL:结构化查询语言(Structured Query Language)简称SQL,是一种专门用来和关系型数据库通信的标准语言,用于向数据库存取数据以及查询、更新和管理关系数据库系统。
与其他语言(Java, C++...)不同的是, SQL由很少的词构成, 这是希望从数据库读写数据时能以更简单有效的方法进行.
SQL有如下优点
SQL语言不是某个特定的数据库提供的语言, 它是一种数据库标准语言.(最初由美国国家标准局 ANSI于1986年完成第一版SQL标准的定义,即SQL-86).这也就意味着每个关系型数据库都支持SQL语言.
SQL简单易学, 是由多个描述性很强的单词构成, 并且这些单词数量不多.
SQL尽管看上去很简单, 但是非常强有力; 灵活的使用SQL, 可以进行比较复杂的和高级的数据库操作.
SQL不区分大小写(除非在某些数据库使用的时候做了特殊设置-不建议这种行为).
2.2 SQL的基本操作
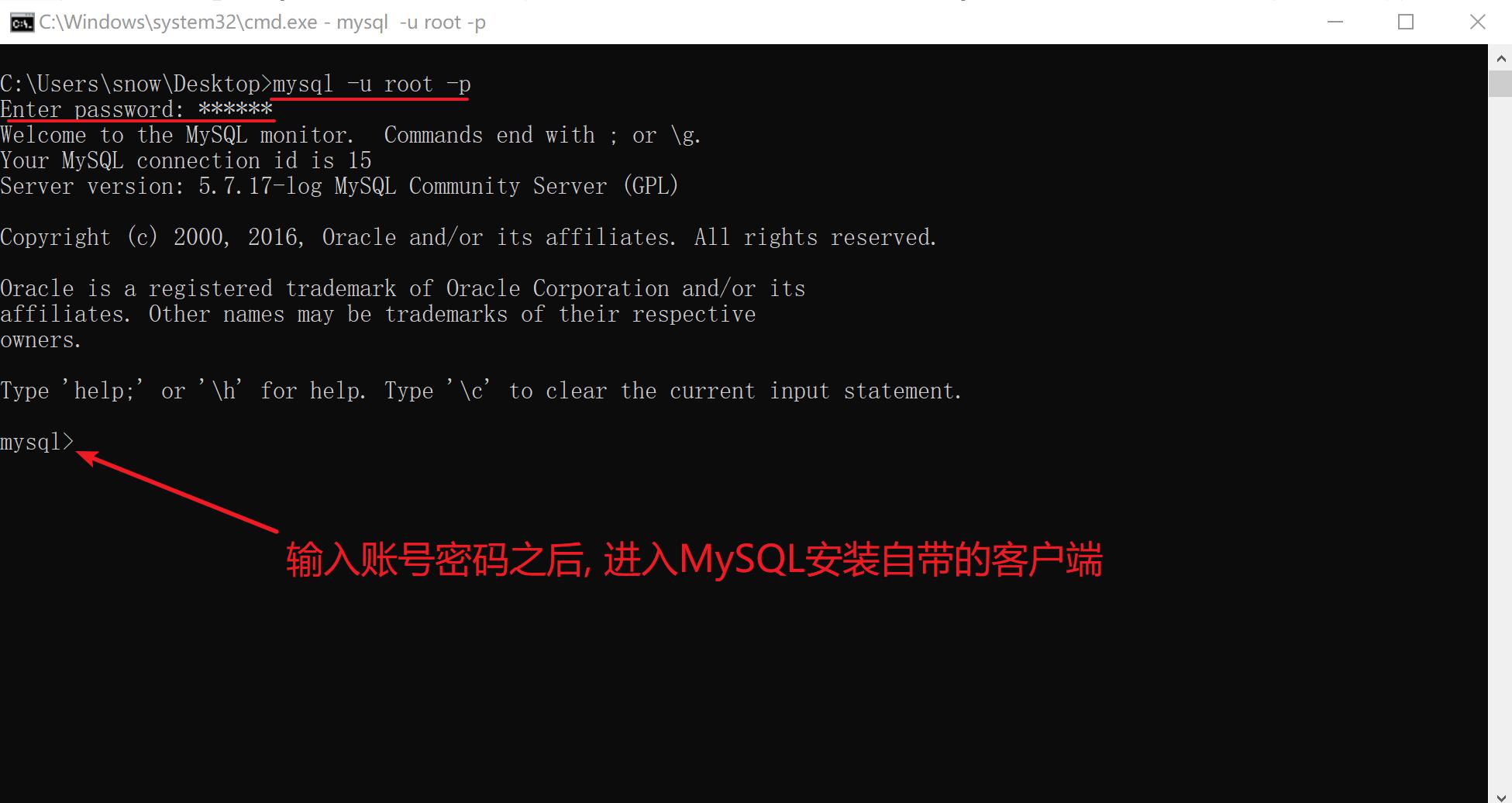
2.2.1 登录数据库
mysql -u root -p [回车]
输入密码
注1 : 注释
xxxxxxxxxx51-- <注释>; # 注释语句2# <注释>; # 注释语句3/*4<注释> # 注释语句5*/注意:
在数据库语句中如果我们需要注释某些内容, 一般有三种方式
--注释符(要注意的是--之后要有一个空格再接着书写注释内容)
#注释符 (之后不需要空格)
/* */注释符 (一般用于多行注释)
注2: 分号
SQL语句应该要以分号作为结束
2.2.2 库操作
查看数据库
show databases; # 查看所有数据库
show databases like '%数据库名%'; # 查看和期望命名相匹配的数据库
show create database 数据库名; # 查看数据库创建信息
xxxxxxxxxx21// show databases like '%数据库名%';2// %代表是一个通配符: 通配0-n个字符
xxxxxxxxxx51 show databases like 'test'; -- 指明就找test2 show databases like '%n'; -- 一个以n字符结束的数据库3 show databases like '%n%'; -- 数据库名字中, 有一个n字符 4
5show create database test; -- 查看之前怎么创建的test数据库(sql语句是什么)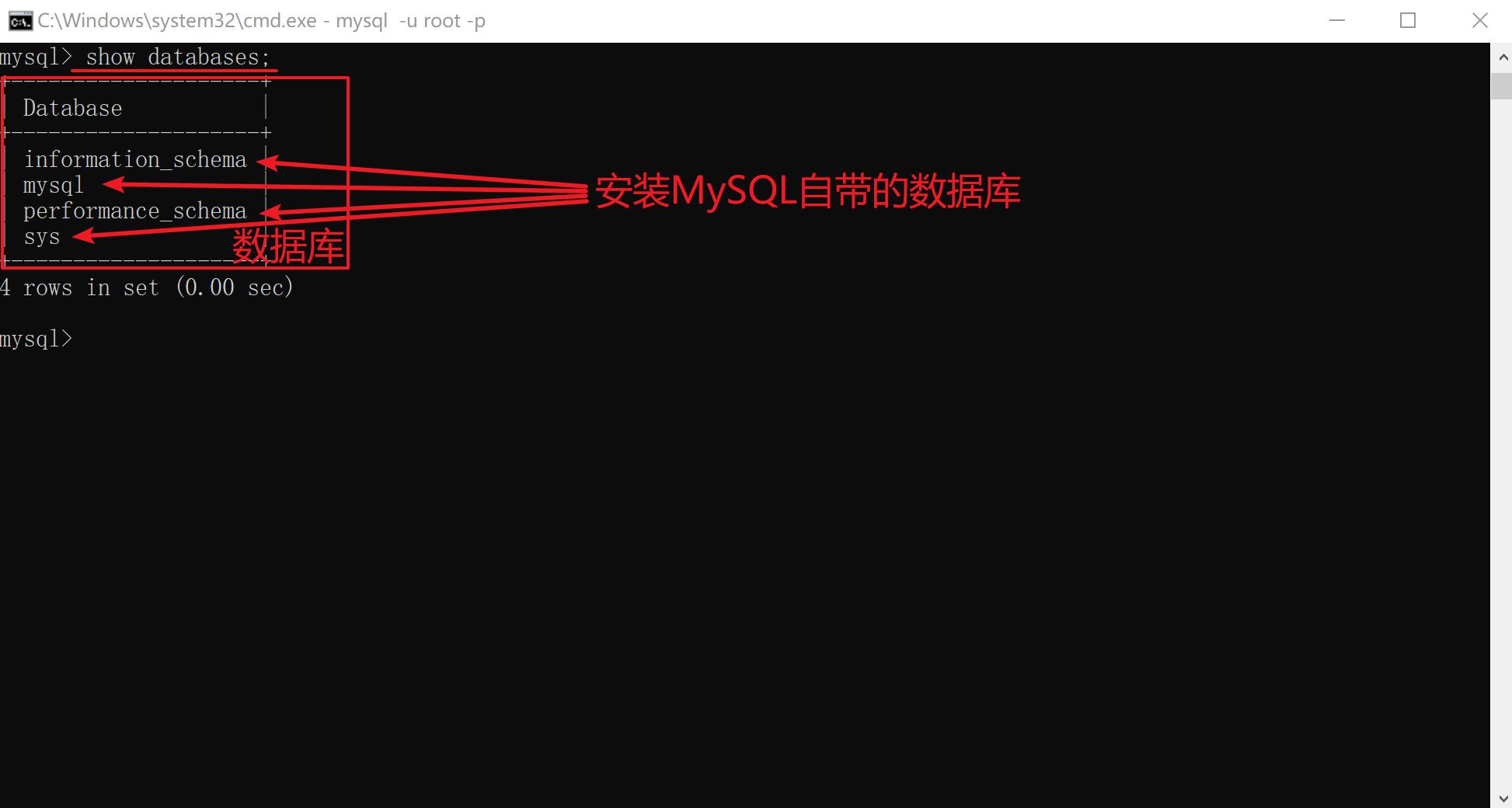
注: 了解(不需要专门记忆)
information_schema:主要存储了系统中的一些
数据库对象信息,比如用户表信息、列信息、权限信息、字符集信息和分区信息等。mysql:MySQL 的核心数据库,主要负责存储数据库
用户、用户访问权限等 MySQL 自己需要使用的控制和管理信息。常用的比如在 mysql 数据库的 user 表中修改 root 用户密码。update mysql.user set authentication_string=password('123456') where user='root';
flush privileges;
performance_schema:主要用于
收集数据库服务器性能参数。sys:sys 数据库主要提供了一些视图,数据都来自于 performation_schema,主要是让开发者和使用者更
方便地查看性能问题。
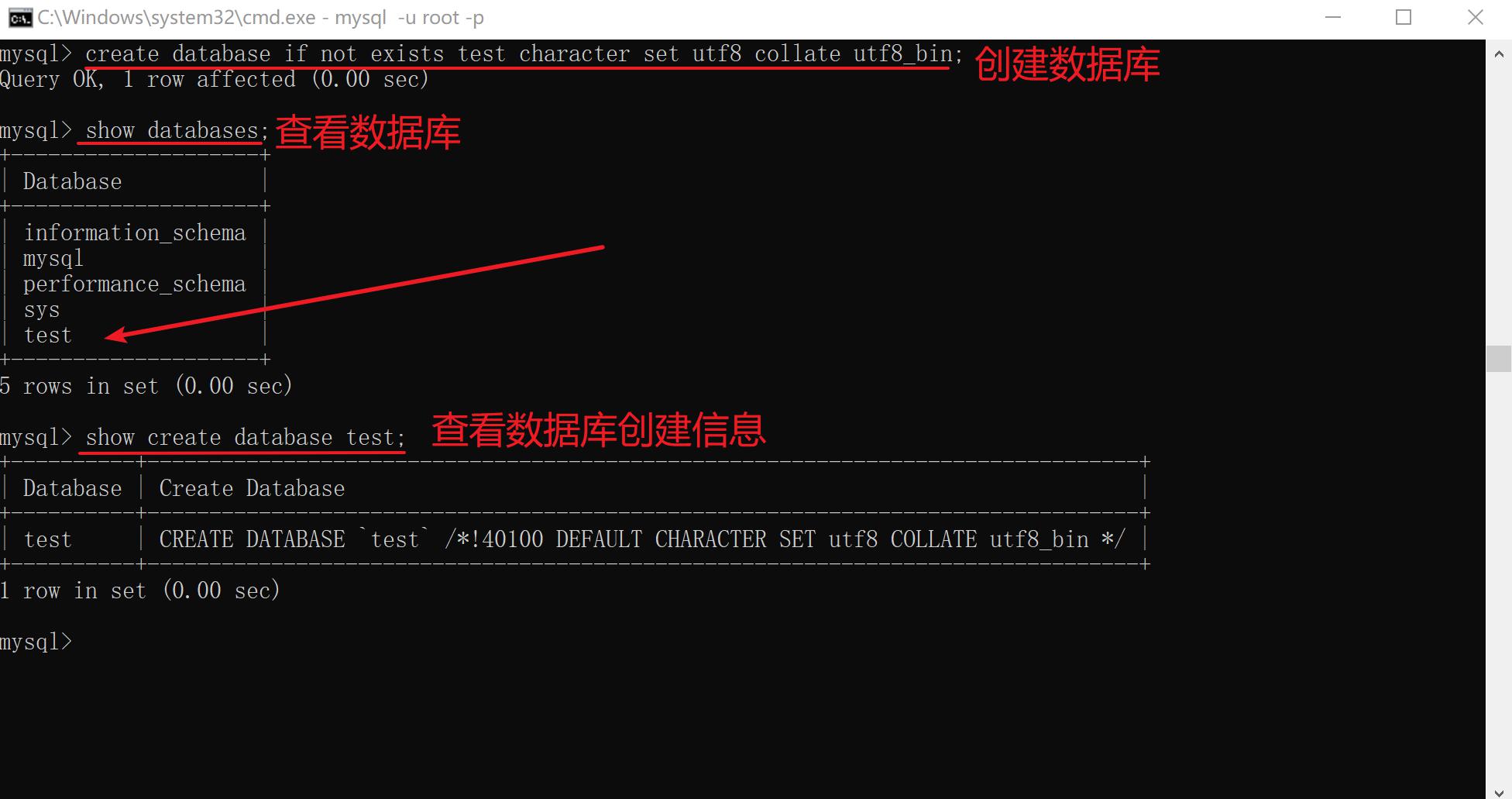
创建数据库
xxxxxxxxxx141CREATE DATABASE [IF NOT EXISTS] <数据库名>2[[DEFAULT] CHARACTER SET <字符集名>]3[[DEFAULT] COLLATE <校对规则名>];4eg:6-- 创建一个db47的数据库, 有可能创建失败直接报错(假如数据库服务里面已经有一个db47的数据库了)8create database db47;9-- 创建一个叫test数据库, 并且要求编码格式是utf8, 还要求排序规则utf8_bin10create database test character set utf8 collate utf8_bin;11-- 如果不存在名字为db47的数据库, 就创建db47, 如果已经存在了db47的数据库, 就不创建(也不报错)12create database if not exists db47;13-- 创建一个指定字符编码格式的和指定排序规则的数据库14create database if not exists test character set utf8 collate utf8_bin;
[ ]可选。<数据库名>:创建数据库的名称。
IF NOT EXISTS:在创建数据库之前进行判断,只有该数据库目前尚不存在时才能执行操作; 如果这个数据库存在, 就不创建/不执行这个sql。
[DEFAULT] CHARACTER SET:指定数据库的字符集。
[DEFAULT] COLLATE:指定字符集的默认校对规则。
注:一些注意事项
注意我们MySQL创建数据库的时候, 如果没有指明编码格式, 那么创建出了数据库在存储字符串的时候, 很多系统默认使用latin1的编码格式 (latin1存储一个字符的时候一个字符占用1个字节, 并且不能存储中文, 中文没有办法用一个字节表示: 所以在实际工作的时候, 我们更应该使用utf8 or utf8mb4)
MySQL中字符集: UTF8 和UTF8MB4的区别
xxxxxxxxxx41// (1) 5.5.3 版本以后的才支持UTF8MB42// (2) UTF8MB4是 UTF8 的超集并完全兼容UTF8。3// (3) UTF8(也称UTF8MB3),1汉字字符使用3字节存储。4// (4) UTF8MB4,1表情字符使用4字节存储。(专门用来兼容4字节的UNICODE编码-平面设计-Emoji问题)。
MySQL中几个了解的校对规则: 了解(不用记具体的排序规则, 只需要知道排序规则是干什么,是对谁起效果的)
xxxxxxxxxx81校对规则/排序规则也可以称为排序规则,是指在字符与字符之间的比较规则。一个字符集有多种校对规则,每个字符集都有一个默认的校对规则。2eg: UTF8MB4: 下面只是用来举例说明, 不用记4// (1) UTF8MB4_GENERAL_CI: (默认规则),字符之间逐个比较,不区分大小写,在排序和比较效率更高。5// 一些特殊字符不能做到精准排序。6// 其实就是没有实现Unicode排序规则, 影响上实际并无所谓。7// (2) UTF8MB4_UNICODE_CI: 基于标准的Unicode来排序和比较,精确排序, 不区分大小写。8// (3) UTF8MB4_BIN: 字符直接用二进制数据编译存储,区分大小写,而且可以存二进制的内容。
删除数据库
在工作中不要删除数据库, 哪怕这个数据库已经没有任何用处了 ( 任何数据都是有价值的, 哪怕是错的数据)
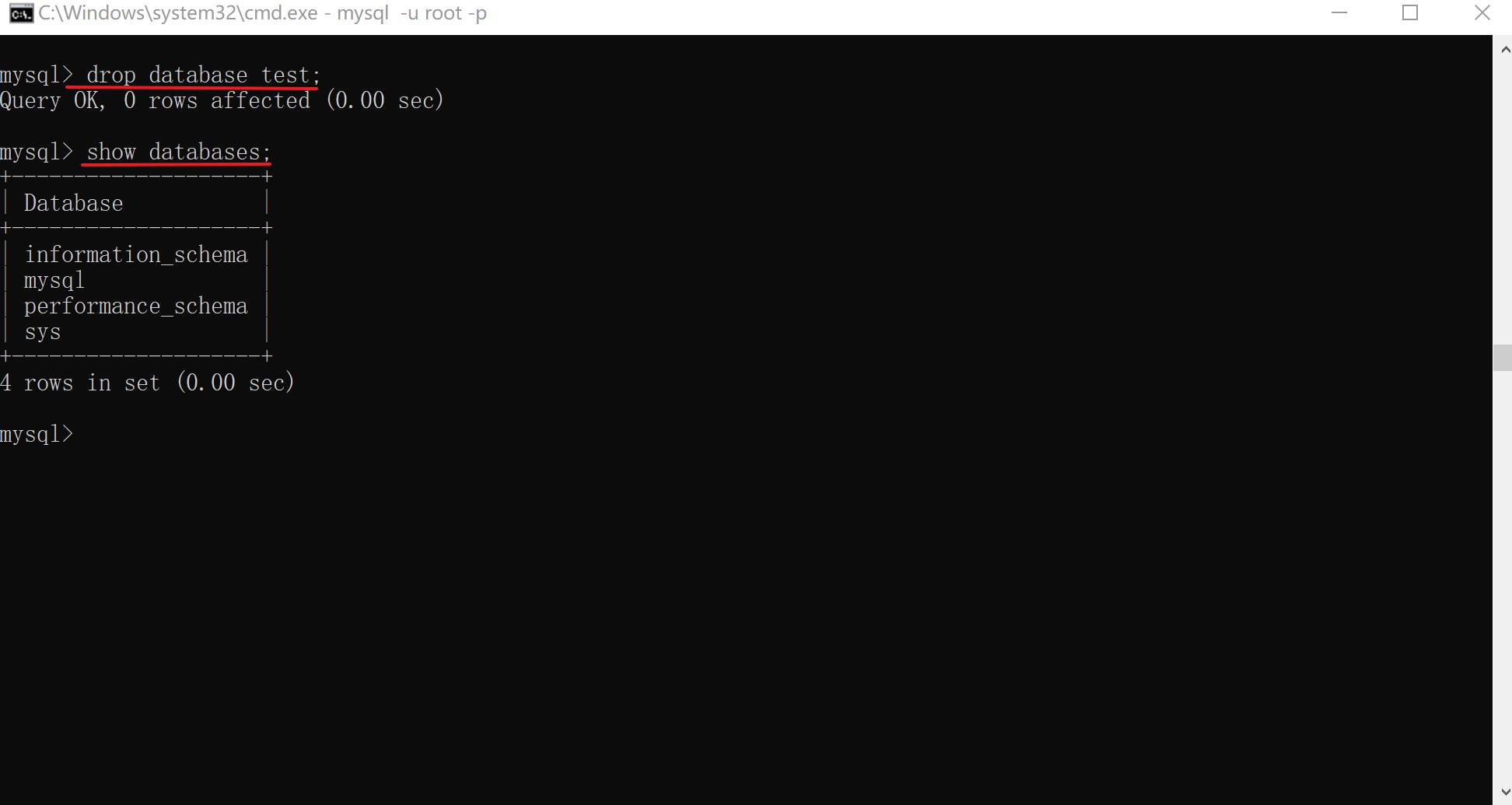
xxxxxxxxxx31DROP DATABASE [IF EXISTS] <数据库名>; # 删除数据库2eg: drop database test; # 删除test数据库
修改数据库
在工作中不要修改数据库, 因为没有任何意义
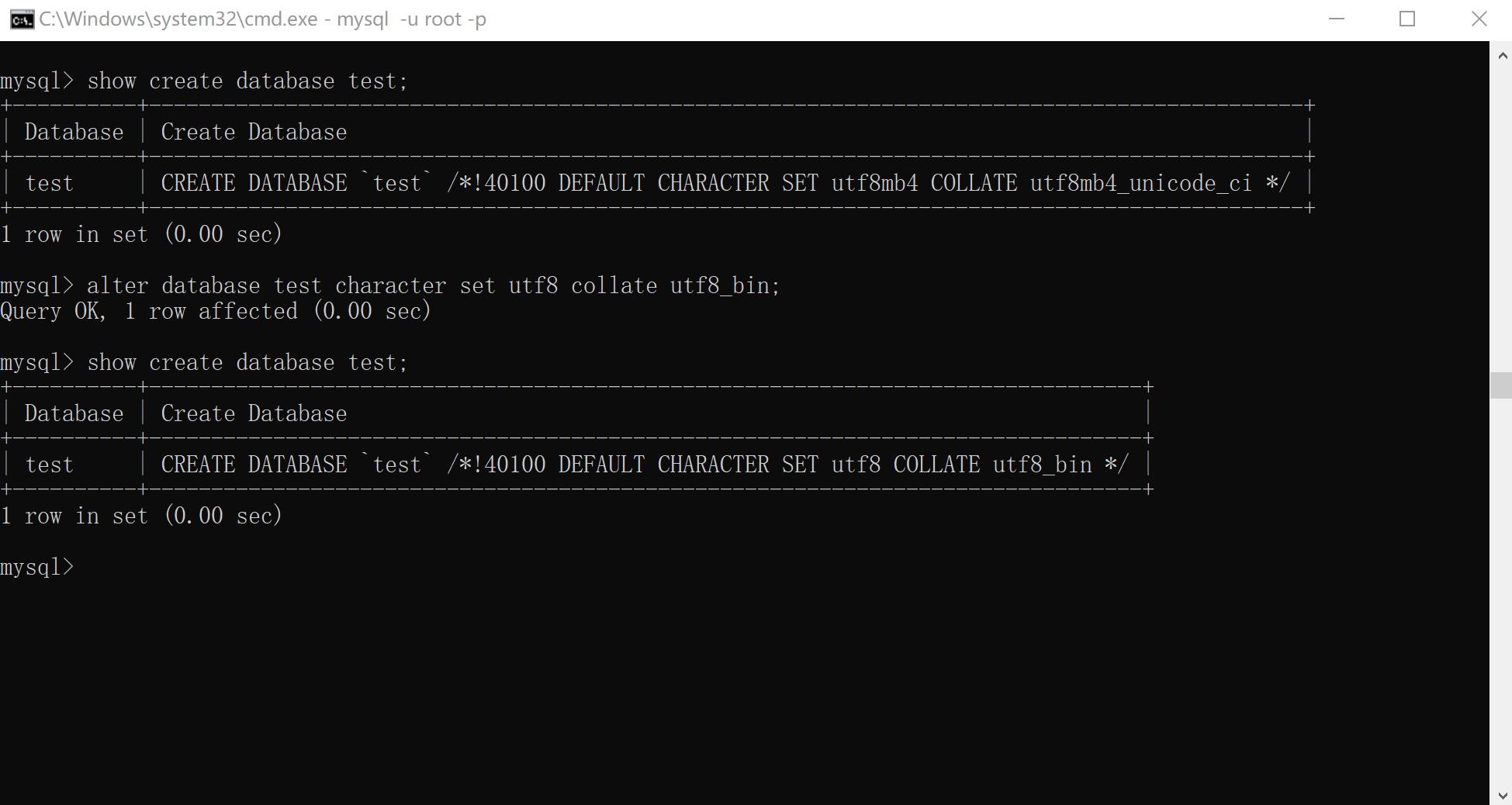
xxxxxxxxxx51ALTER DATABASE [数据库名]2{ [ DEFAULT ] CHARACTER SET <字符集名> | [ DEFAULT ] COLLATE <校对规则名> }3eg: alter database test character set utf8 collate utf8_bin; # 把test数据库的编码改成utf8, 校对规则改为utf8_bin数据库中只提供了对数据库使用的字符集和校对规则修改操作。
xxxxxxxxxx81假设一种场景: 举个例子2// 第一步: 先创建了一个数据库: create database th54 character set utf8;3// 编码格式是utf84// 第二步: 在这个数据库th54中创建一个表: studnets->utf8. (如果在创建表的时候没有指明编码格式, 默认跟随数据库的编码格式)5// 第三步: 修改了th54的编码格式: alter database th54 character set utf8mb4;6// th54的编码格式已经修改为utf8mb47// studnets编码格式会不会跟着变? 默认不会, 还是utf88// 第四步: 创建一个全新的User表 : User -> utf8mb4
选择数据库
xxxxxxxxxx41USE <数据库名>; # 选择数据库2eg:4use test; # 选择test数据库一个MySQL系统中, 管理多个数据库。 我们只有进入对应的数据库中, 才能进一步操作数据库中的表和数据。

2.2.3 表操作
常见的数据类型
数据类型(DATA_TYPE)是指数据库所允许的数据的类型。
MySQL是一个数据存储容器, 数据类型定义了可以存储什么类型数据的规则。
数据库是由多张表构成。其中每个表中对应的数据列, 都应该有适当的数据类型,用于限制或允许该列中存储的数据。
(1) 整数
| MySQL的整数类型 | 占用字节 | 有符号 | 无符号 | 说明 |
|---|---|---|---|---|
| TINYINT(M) | 1 | -128 ~ 127 | 0 ~ 255 | 很小的整数 |
| INT/INTEGER(M) | 4 | -231 ~ 231-1 | 0 ~ 232-1 | 普通整数 |
| BIGINT(M) | 8 | -263 ~ 263-1 | 0 ~ 264-1 | 大整数 |
注意1:
INT和INTEGER在MySQL中并无区别, 仅是缩略写法.link。
注意2: 关于
整数设置'长度/宽度'问题。第一原则:无论给整数设置什么长度都不违背上述'有/无符号'表示的存储范围(上述范围表示是一切基本标准)。
第二原则: 设置长度之后, 如果存储的整数长度小于指定长度, 会默认在数字位前自动补空格, 以满足指定长度(但是补的空格这是不可见的), 也可以选择经过设置使用0填充; 设置长度之后, 如果存储的整数长度大于指定长度, 如果在表示范围内, 不做切割/不做处理(不补0, 也不补空格), 直接存储。
xxxxxxxxxx61CREATE TABLE `tb_test` (2`id` int NOT NULL,3`age` int ZEROFILL NULL, -- zerofill: 填充04`height` int(3) unsigned NOT NULL,5PRIMARY KEY (`id`)6);
(2) 浮点数
| MySQL的浮点数 | 占用字节 | 说明 |
|---|---|---|
| FLOAT(M, D) | 4 | 单精度 |
| DOUBLE(M, D) | 8 | 双精度 |
M: 精度, 表示总数据位数。 取值范围为(1~255)。
D: 标度, 表示小数位的位数。 取值范围为(1~30,且不能大于 M-2)。
需要注意的是: int类型设置宽度只是要不要填充空格和0的问题, 在float double中这个设置参数超过总位数会报错, 超过小数位限制舍弃
FLOAT 和 DOUBLE 在不指定精度时,默认会按照实际的精度(由计算机硬件和操作系统决定)。
xxxxxxxxxx71-- FLOAT 类型的取值范围如下:2有符号的取值范围:-3.402823466E+38~-1.175494351E-38。3无符号的取值范围:0 和 -1.175494351E-38~-3.402823466E+38。4-- DOUBLE 类型的取值范围如下:6有符号的取值范围:-1.7976931348623157E+308~-2.2250738585072014E-308。7无符号的取值范围:0 和 -2.2250738585072014E-308~-1.7976931348623157E+308。
(3) 日期
| MySQL日期 | 字节 | 日期格式 | 表示范围 |
|---|---|---|---|
| YEAR | 1 | YYYY | 1901 ~ 2155 |
| TIME | 3 | HH:MM:SS | -838:59:59 ~ 838:59:59 |
| DATE | 3 | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| DATETIME | 8 | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP | 4 | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
year/YEAR范围: 1901~ 2155包含255个年份, 对应一个字节表示范围。
time/TIME范围: 11111111111111111111111(23位剩余一位符号位)--> 8388607(十进制)
8388607: 838(小时位) xx(描述分钟) xx(描述秒)。 (计算方式不用记)
timestamp/TIMESTAMP范围: (时间戳) (一般用于一些计时, 倒计时, 数据传输 ......) (秒数1)
1970年1月1日作为UNIX TIME的纪元时间(开始时间)。
xxxxxxxxxx111--2create table user(3id int,4name varchar(5),5height float(5, 2),6birthday datetime,7tag_time timestamp8)9--10insert into user4 values(1, 'zs', 188.01, '2000-11-12 55:30:12', '2000-01-01 00:00:00');11insert into user4 values(1, 'zs', 188.01, '2000-11-12 10:30:12', now());
(4) 字符串
| MySQL字符串 | 内存占用 | 说明 |
|---|---|---|
| CHAR(M) | (M * 单个字符占用字节) | 固定长度字符串 |
| VARCHAR(M) | L+1字节 or L+2字节 。 | 变长字符串 |
| TEXT(M) | L+2字节 。 L: 0~216 | 变长文本字符串 |
| LONGTEXT(M) | L+4字节 。 L: 0~232 | 变长大文本字符串 |
L: 存储字符的实际长度。
M: 列的指定长度。
CHAR (M不设置默认为1) 范围可以设置最大255 。
VARCHAR(M不设置会报错) 最大长度为 65,535字节
TEXT 最大长度为 65535字符
LONGTEXT 最大长度长度为 4294967295 字符。
1, 数据库中的char可以正常存储字符串: eg: "zs", "我爱学习" ....; (但是一般我们用到的char的时候, 更多是为了存储类似性别这种具有固定长度和格式的短字符串)
2, 创建表的时候, 如果使用char类型, 不加宽度/长度, 长度默认为1; 如果使用varchar不加长度/宽度, 创建的时候会报错, text/longtext同样建议指明长度(有些版本中不指明会报错)
3, 在数据库中, 只要是字符串, 都有长度限制, 在字符串列存储数据的时候, 不能超出既定的长度限制 (字符串的长度限制是一个严格限定).
4, 如果使用char类型(
定长字符串), 它是一个固定长度字符串: 如果我们常见char的时候指明的宽度为m, 每一个这个char列的数据, 最终开辟的内存空间为: 单个字符占用空间 * M; 和实际存储了几个字符无关5, 我们使用varchar这种
变长字符串存储数据的的时候, 字符串实际占用的内存空间和我们给varchar设置的宽度/长度没有任何关系, 只和这个varchar列实际存储的字符个数有关.
查看表
xxxxxxxxxx41SHOW TABLES; # 查看该数据库中所有表2SHOW CREATE TABLE <表名>; # 查看表的创建语句3DESCRIBE <表名>; # 查看表结构4DESC <表名>; # 查看表结构
创建表
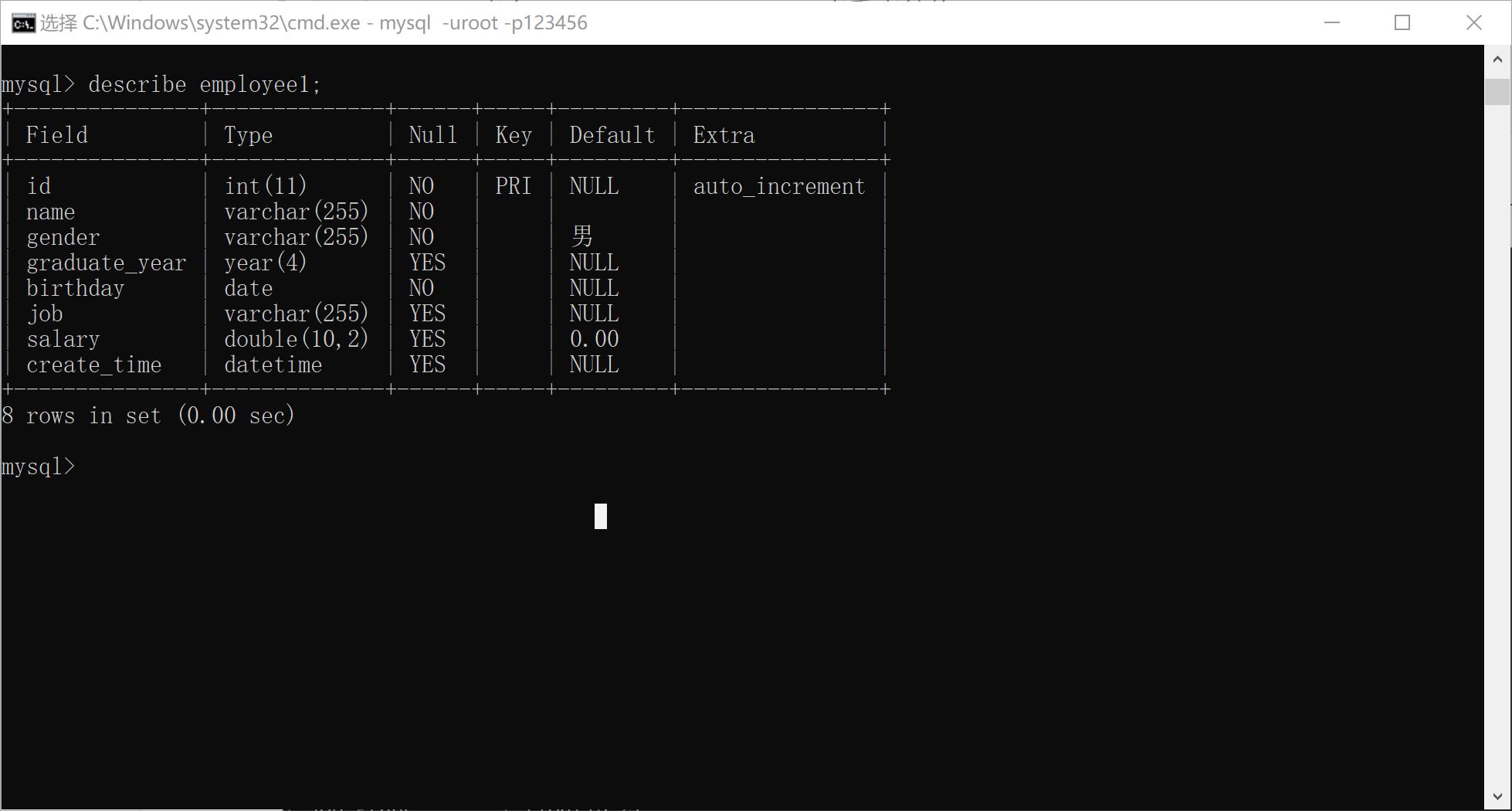
xxxxxxxxxx291CREATE TABLE <表名> (2<列名1> <类型1> ,3[…] ,4<列名n> <类型n>5) [表选项] [分区选项];6eg1:8create table employee(9id int ,10name varchar(20),11gender char,12birthday date,13job varchar(20),14salary double(10,2)15)character set utf8 collate utf8_bin;16-- 不推荐专门给一个表设置编码格式(没什么用, 只会让一个数据库编码格式不统一)(建议不设编码格式: 表的编码格式遵从数据库设置的编码格式)17eg2: 仅仅是个完善的写法示例, 一些写法完全没有必要(比如重复设置字符编码格式), 比如注释19CREATE TABLE employee1 (20id int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',21name varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '姓名',22gender varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '男' COMMENT '性别',23graduate_year year NULL DEFAULT NULL COMMENT '毕业时间',24birthday date NOT NULL COMMENT '生日',25job varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '职位名称',26salary double(10, 2) NULL DEFAULT 0.00 COMMENT '薪资',27create_time datetime NULL DEFAULT NULL COMMENT '信息创建时间',28PRIMARY KEY (id) USING BTREE29) ;
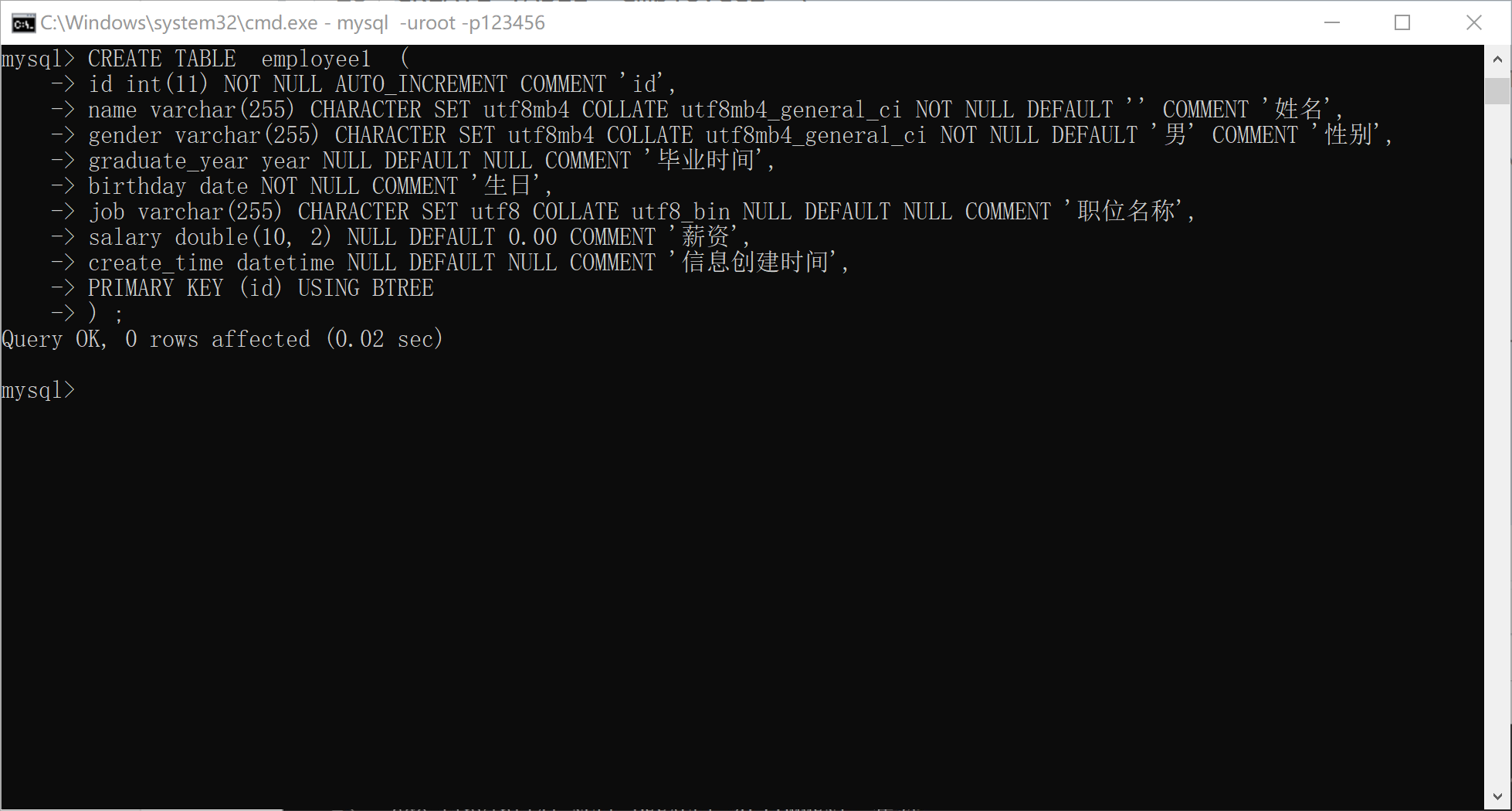
主键和自增问题
主键(PRIMARY KEY)又被称为''主键约束'',是 MySQL中使用非常频繁的约束。它有诸多作用(唯一标识, 查找效率...)。
注意1:
xxxxxxxxxx61-- 主键: 如果一个表中给某一列设置了主键, 那么这一列强制不能重复, 如果存储重复的主键会自动报错2-- 主键: 不允许是null, 存储null主键, 报错3-- 每个表只能定义一个主键。4-- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在有相同主键值的两行数据。5ps: 如果用户没有定义主键,也没有定义索引,那么InnoDB引擎会在创建表的时候, 自动生成一个不可见的ROW_ID的列名的聚簇索引,该列是一个6字节的自增数值,随着插入而自增, 来起到主键的作用。主键分类:
xxxxxxxxxx281主键分为单字段主键和多字段联合主键2-- 单字段主键: 既将表中的一个字段设置主键; 通过 PRIMARY KEY 关键字来指定主键.3CREATE TABLE table_primary1(4id INT(11) PRIMARY KEY , -- 主键5name VARCHAR(25),6job VARCHAR(25),,7salary FLOAT8);9CREATE TABLE table_primary2(10id INT(11),11name VARCHAR(25),12job VARCHAR(25),13salary FLOAT,14PRIMARY KEY(id)15);16-- 如果一个表表在创建的时候没有主键, 增加主键的sql18-- alter table 表名 add primary key (主键列);19alter table user add primary key (id);20-- 联合主键: 复合主键(不建议)。这意味着id和name的组合在table_primary3表中表示主键。22CREATE TABLE table_primary3(23id INT(11),24name VARCHAR(25),25job VARCHAR(25),26salary FLOAT,27PRIMARY KEY(id, name)28);注意2: 唯一键: 仅了解
xxxxxxxxxx131// 唯一键(Unique Key)是数据库中的一个约束,用于确保表中的所有记录在指定的一列或列组合上是唯一的。即:组合唯一。2// 与主键不同的是,唯一键允许有空值(NULL)。3// 表中可以有多个唯一键约束。4// 在某些情况下,唯一键也可以作为主键的一部分。5CREATE TABLE table_primary3(7id INT(11),8name VARCHAR(25),9job VARCHAR(25),10salary FLOAT,11primary KEY(id),12unique key (job, salary)13);注意3: 自增问题 AUTO_INCREMENT
xxxxxxxxxx171CREATE TABLE table_primary1(2id INT(11) PRIMARY KEY AUTO_INCREMENT , -- 主键3name VARCHAR(25),4job VARCHAR(25),,5salary FLOAT6);7-- AUTO_INCREMENT 的初始值是 1,数据增加一条,该字段值自动加 1。8-- 建议: 一个表中应该只有一个字段使用 AUTO_INCREMENT 约束,且该字段一般位为作为索引/主键的id字段。9-- AUTO_INCREMENT 字段应该要设置 NOT NULL 属性。10-- AUTO_INCREMENT 约束的字段只能是整数类型。11-- AUTO_INCREMENT 上限为所约束的类型的数值上限。12-- 如果一个表表在创建的时候某些列没有自增, 设置自增14-- alter table 表名 modify 列名 int auto_increment;15alter table user modify id int auto_increment;16
修改表
表的修改操作:不允许在工作直接修改表
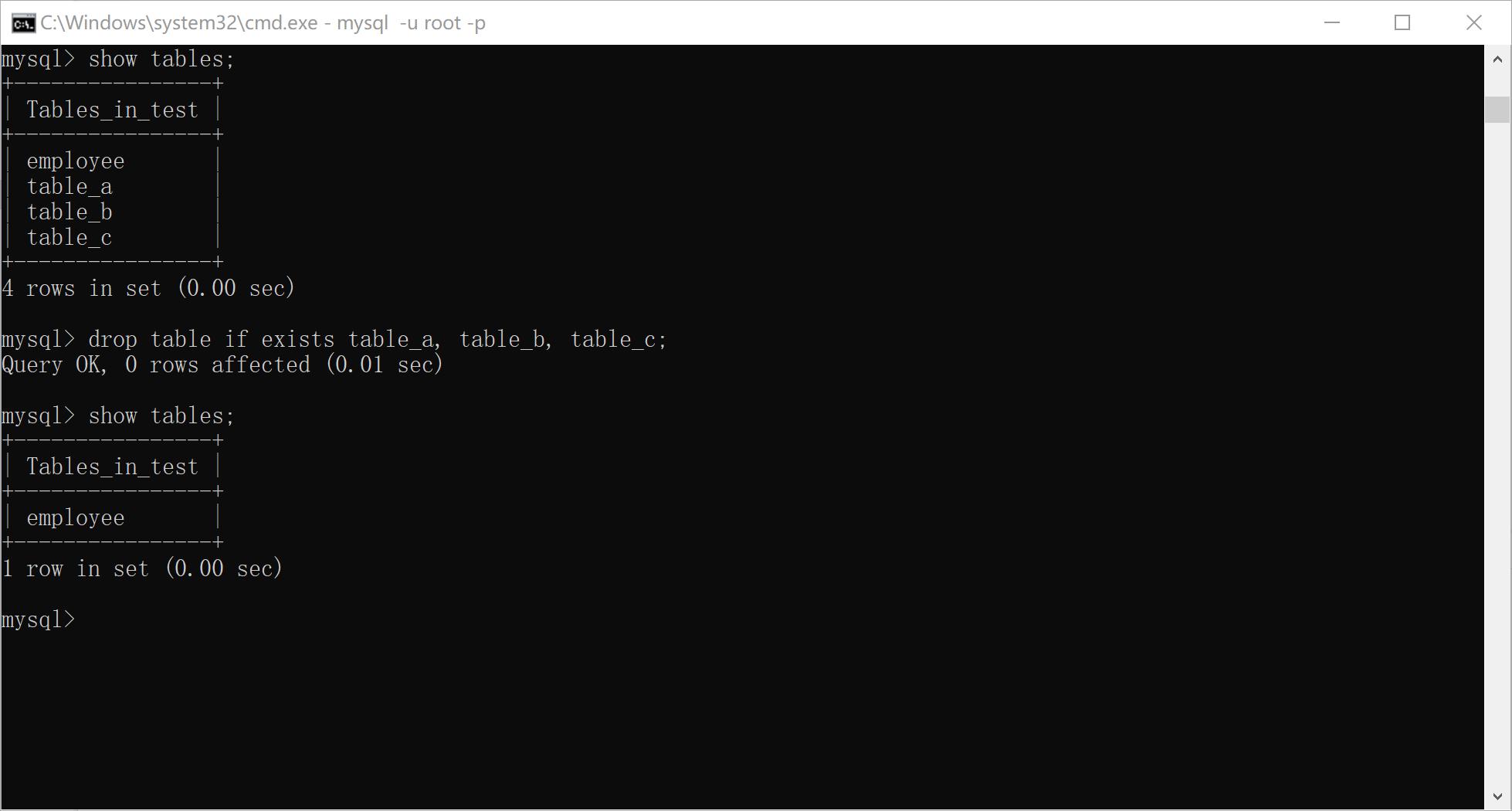
xxxxxxxxxx321ALTER TABLE <表名> ADD COLUMN <列名> <类型>; # 添加列2ALTER TABLE <表名> ADD <新字段名> <数据类型> FIRST; # 头位置添加列3ALTER TABLE <表名> ADD <新字段名> <数据类型> AFTER <已经存在的字段名>; # 指定位置添加列4ALTER TABLE <表名> MODIFY COLUMN <列名> <类型>; # 修改某列类型5ALTER TABLE <表名> CHANGE COLUMN <旧列名> <新列名> <新列类型>; # 修改列及类型6ALTER TABLE <表名> ALTER COLUMN <列名> SET DEFAULT <默认值>; # 修改某列默认值7ALTER TABLE <表名> ALTER COLUMN <列名> DROP DEFAULT; # 删除某列默认值8ALTER TABLE <表名> DROP COLUMN <列名>; # 删除某列9ALTER TABLE <表名> RENAME TO <新表名>; # 修改表名10ALTER TABLE <表名> RENAME AS <新表名>; # 修改表名11ALTER TABLE <表名> RENAME <新表名>; # 修改表名12RENAME TABLE <表名> TO <新表名>; # 修改表名13ALTER TABLE <表名> CHARACTER SET <字符集名>; # 修改表字符集14ALTER TABLE <表名> COLLATE <校对规则名>; # 修改表排序规则15ALTER TABLE <表名> [DEFAULT] CHARACTER SET <字符集名> [DEFAULT] COLLATE <校对规则名>;16eg:18alter table employee add column height float(5,2);19alter table employee add column height float(5,2) first;20alter table employee add column height float(5,2) after name;21alter table employee modify column age float(5, 0);22alter table employee change column age age1 float(5, 0);23alter table employee alter column age set default 20;24alter table employee alter column age drop default;25alter table employee drop column height;26alter table employee rename to aaa;27alter table aaa rename as employee;28alter table employee rename aaa;29rename table aaa to employee;30alter table employee character set utf8mb4;31alter table employee collate utf8mb4_unicode_ci;32alter table employee character set gbk collate gbk_bin;
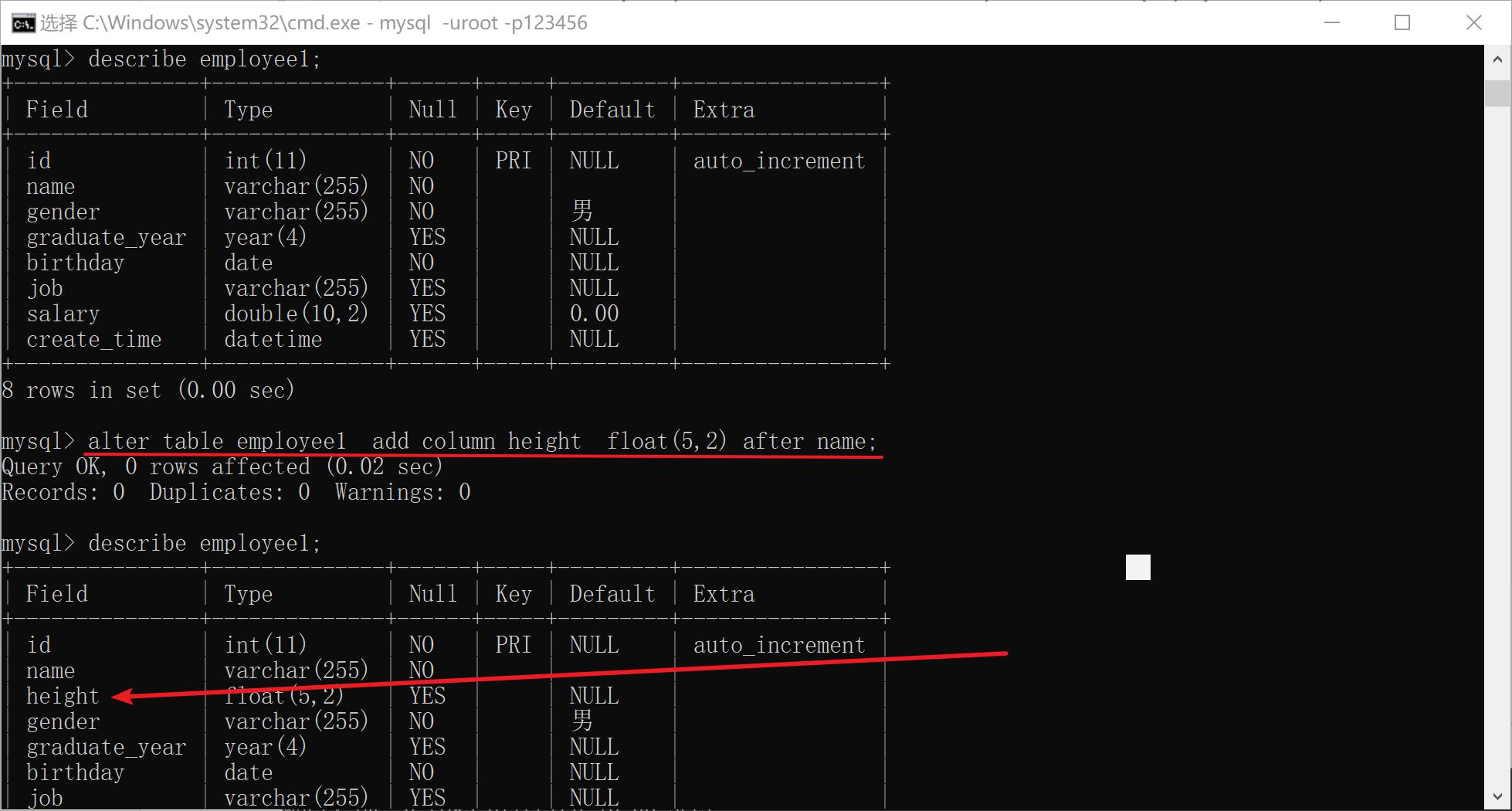
删除表
不允许在工作直接删除表
更不建议: 任何数据都是有意义的
xxxxxxxxxx41DROP TABLE [IF EXISTS] 表名1 [ ,表名2, 表名3 ...]2eg:4drop table if exists table_a, table_b, table_c;
2.2.4 数据操作
添加数据
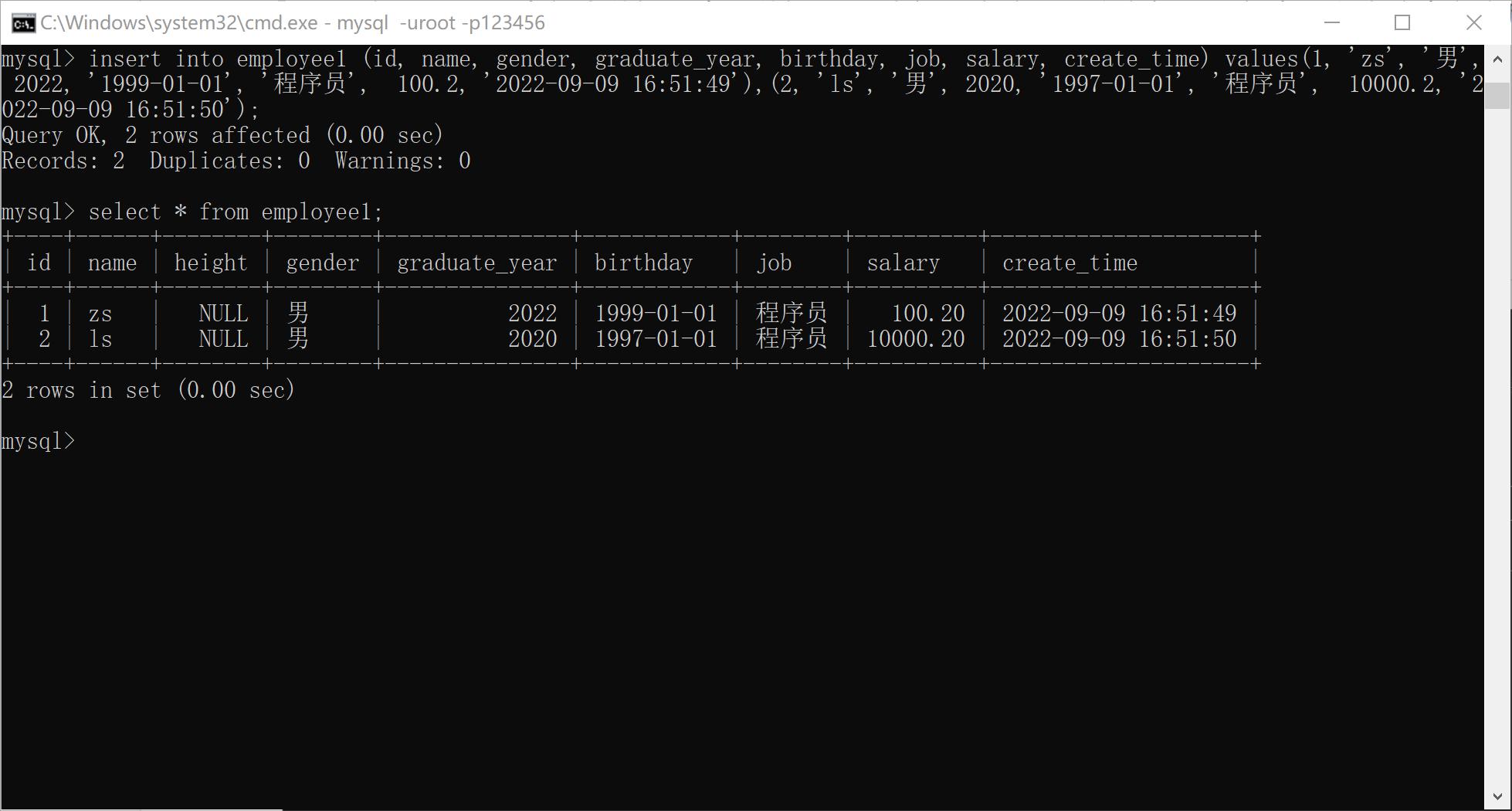
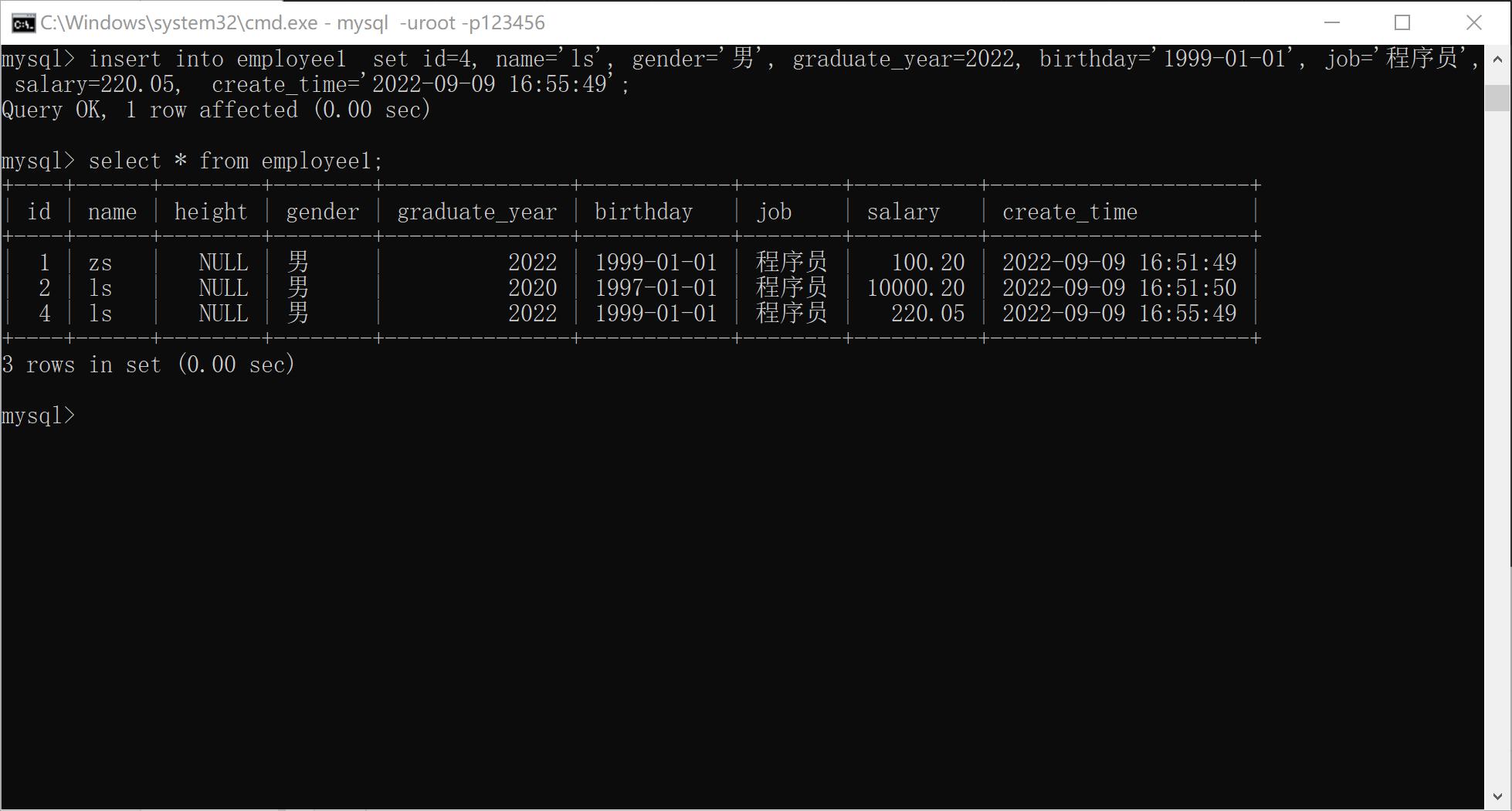
xxxxxxxxxx91INSERT INTO <表名> [ (<列名1>, … <列名n> )] VALUES (值1, … 值n), … (值1, … 值n);2INSERT INTO <表名> SET <列名1>=<值1>, … <列名n>=<值n>;3eg:5insert into employee1 (id, name, gender, graduate_year, birthday, job, salary, create_time) values(1, 'zs', '男', 2022, '1999-01-01', '程序员', 100.2, '2022-09-09 16:51:49');6insert into employee1 (id, name, gender, graduate_year, birthday, job, salary, create_time) values(1, 'zs', '男', 2022, '1999-01-01', '程序员', 100.2, '2022-09-09 16:51:49'),(2, 'ls', '男', 2020, '1997-01-01', '程序员', 10000.2, '2022-09-09 16:51:50');8insert into employee1 set id=4, name='ls', gender='男', graduate_year=2022, birthday='1999-01-01', job='程序员', salary=220.05, create_time='2022-09-09 16:55:49';
如果values中包含数据和表列数据一一对应(无省略), 那么在插入语句中可以省略表名之后表列的一一列举。eg: insert into 表名 values (值1, … 值n);
values中的内容应该要与对应插入字段对应。
数据中字符串和日期应该包含在引号中。
查询数据
xxxxxxxxxx81SELECT * FROM <表名字> [ WHERE <条件> ];2SELECT <列名1>, …<列名n> FROM <表名字> [ WHERE <条件> ];3eg:5select * from employee1;6select * from employee1 where id<20;7select name from employee1 where id>1;8select name, job, salary from employee1 where salary> 200;
查询的结果是一个新的临时表。
在MySQL中
select * from 表名 where 1;表示查询所有数据。

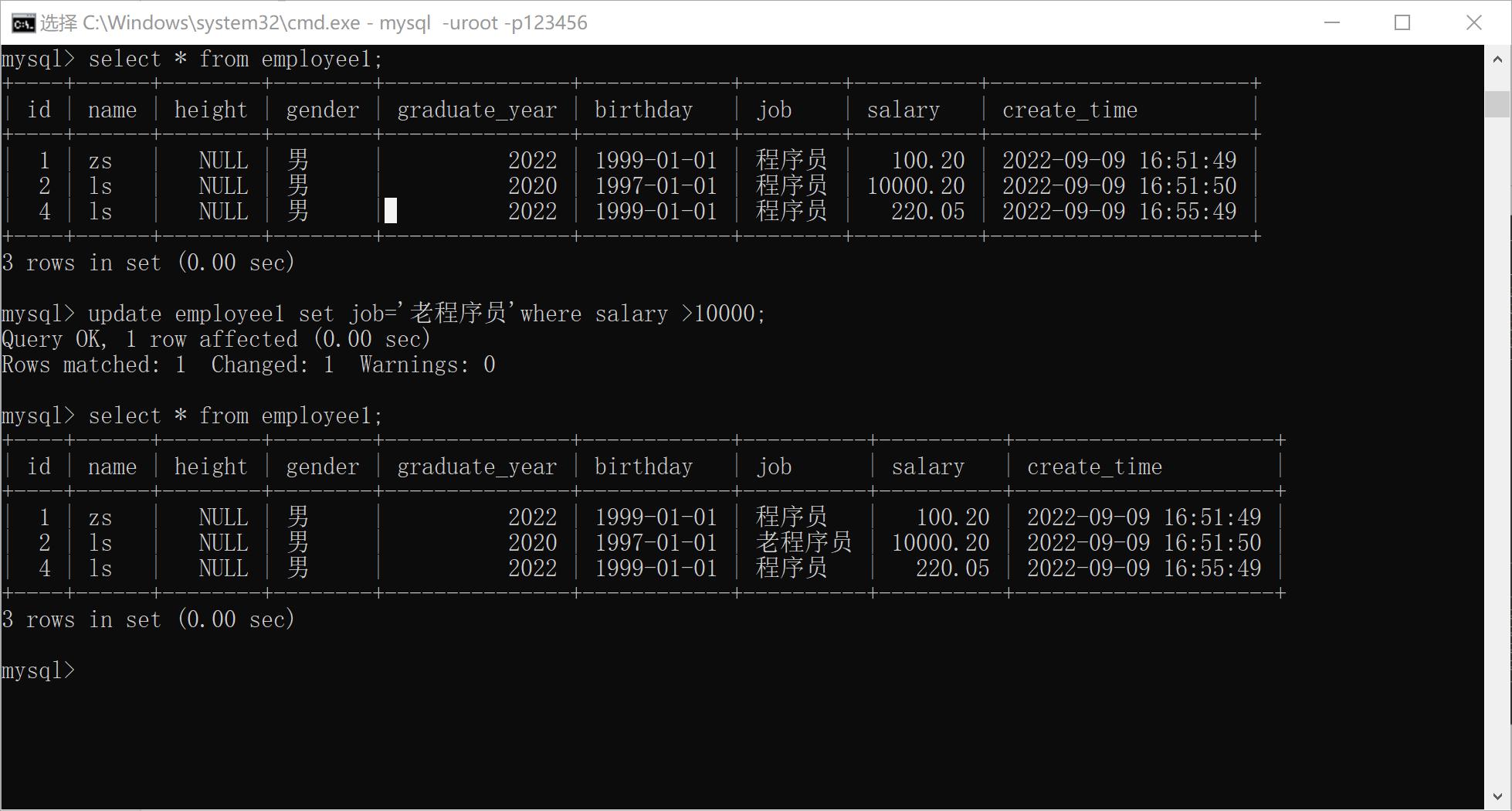
修改数据
xxxxxxxxxx41UPDATE <表名> SET 列1=值1 [, 列2=值2 … ] [WHERE <条件> ]2eg:4update employee1 set job='老程序员' where salary >10000;
注意如果没有where子句指明条件, 那么修改就是对所有行的修改。
修改一行数据的多个列值时,SET 子句的每个值用逗号分开即可。
删除数据
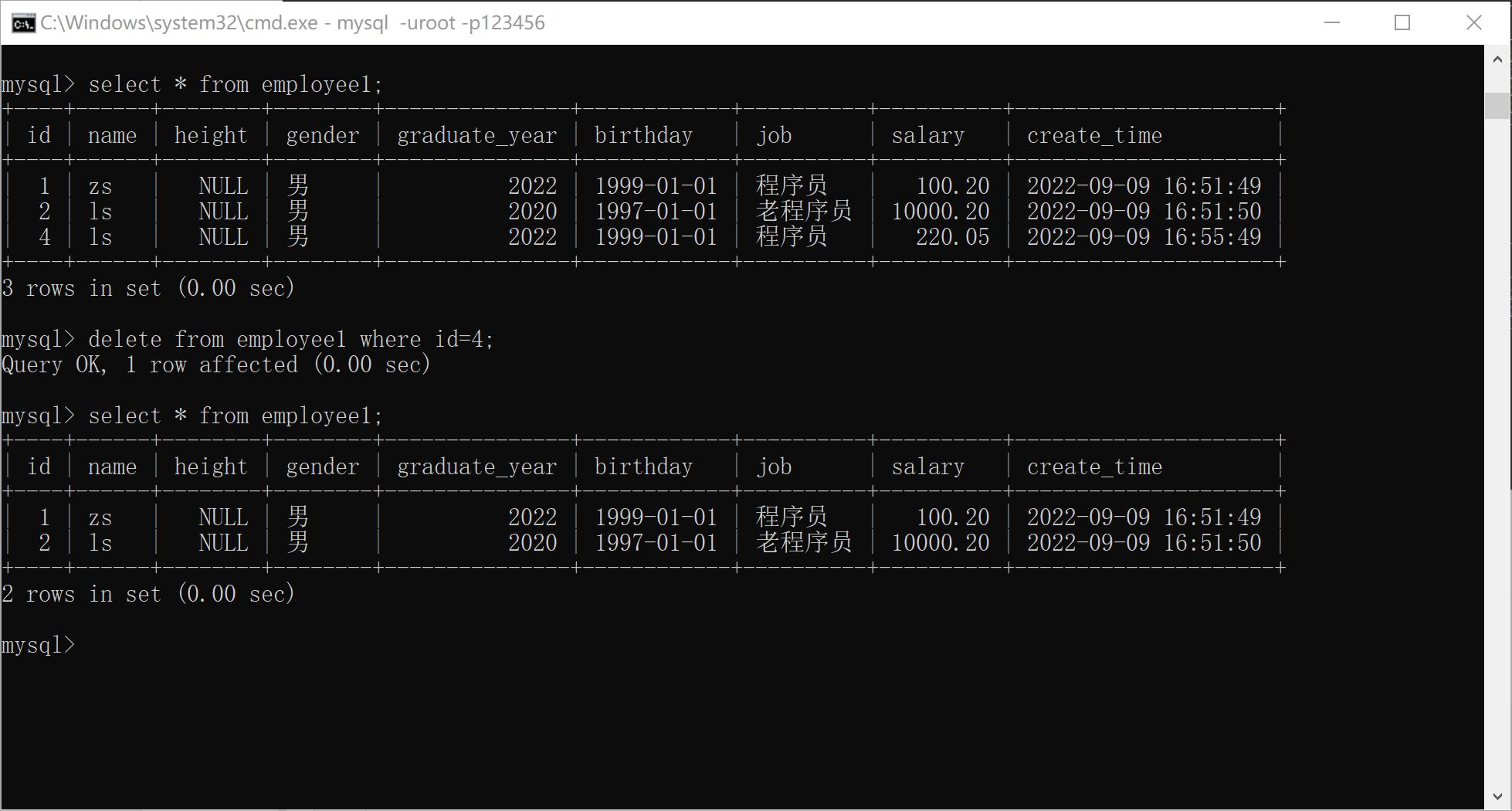
在工作中删除数据, 一般是逻辑删除
xxxxxxxxxx51DELETE FROM <表名> [WHERE <条件>]2ag:4delete from employee;5delete from employee where id=4;
如果没有where以及条件, 默认删除是表中所有数据。
delete不能单独只删除某一列数据, delete删除数据的最小单元为行。
delete语句仅删除数据记录, 删除的不是表, 如果要删除表需要使用drop table语句。
2.3 特殊关键字
数据基础
xxxxxxxxxx81CREATE TABLE `students` (2`id` int(11) PRIMARY KEY AUTO_INCREMENT,3`name` varchar(255) ,4`class` varchar(255) ,5`chinese` float ,6`english` float ,7`math` float8) ;xxxxxxxxxx131INSERT INTO students (id, name, class, chinese, english, math) VALUES (1, '武松', '一班', 70, 90, 60);2INSERT INTO students VALUES (2, '林冲', '一班', 70, 90, 90);3INSERT INTO students VALUES (3, '松江', '一班', 90, 90, 20);4INSERT INTO students VALUES (4, '贾琏', '二班', 60, 60, 60);5INSERT INTO students VALUES (5, '贾宝玉', '二班', 95, 80, 5);6INSERT INTO students VALUES (6, '贾环', '二班', 25, 25, 5);7INSERT INTO students VALUES (7, '曹操', '三班', 90, 90, 90);8INSERT INTO students VALUES (8, '曹丕', '三班', 90, 80, 80);9INSERT INTO students VALUES (9, '曹植', '三班', 98, 90, 80);10INSERT INTO students VALUES (10, '刘备', '三班', 95, 90, 80);11INSERT INTO students VALUES (11, '诸葛亮', '三班', 98, 95, 95);12INSERT INTO students VALUES (12, '孙权', '三班', 80, 90, 80);13INSERT INTO students (id) VALUES (13);

2.3.1 Where
xxxxxxxxxx41SELECT <查询内容|列等> FROM <表名字> WHERE <查询条件|表达式>2eg:4select id, name from students where id > 10;使用 WHERE 关键字并指定
查询/删除/修改的条件, 让操作在满足条件的情况下执行 数据操作.
在构建Where的
条件的过程中, 我们可能需要了解到一些重要的SQL运算符1, 算术运算符: 可以用在条件中, 也可以用在结果集中
运算符 作用 + 加 - 减 * 乘 / 除 % 取余 xxxxxxxxxx71eg:2select * from students where (chinese + english + math) < 180;3select * from students where (chinese - math) > 30;4select *, (chinese*0.5 + english*0.1 + math *0.4) from students;5select *, (chinese*0.5 + english*0.1 + math *0.4) from students where (chinese*0.5 + english*0.1 + math *0.4) <= 60 ;6select *, (chinese + english + math) /180 from students ;7select *, (chinese + english + math) /180 from students where (chinese + english + math) /180 < 1.2;2, 比较和逻辑运算符
运算符 作用 运算符 作用 = 等于 <=> 等于(可比较null) != 不等于 <> 不等于 < 小于 > 大于 <= 小于等于 >= 大于等于 is null 是否为null is not null 是否不为null between and 在闭区间内 in 是否在列表内 not in 不在列表内 like 通配符匹配(%:通配, _占位) and 与 && 与 or 或 || 或 xxxxxxxxxx201select * from students where chinese = 60;2select * from students where chinese <=> 60;3select * from students where chinese != 60;4select * from students where chinese <=> 60;5select * from students where chinese < 60;6select * from students where chinese > 90;7select * from students where chinese <= 60;8select * from students where chinese >= 90;9select * from students where chinese is null;10select * from students where chinese is not null;11select * from students where chinese between 60 and 90;12select * from students where chinese in (60 , 90);13select * from students where chinese not in (60 , 90);14select * from students where name = '曹操';15select * from students where name like '曹操';16select * from students where name like '曹%';17select * from students where name like '曹%' and chinese = 90;18select * from students where name like '曹%' && chinese = 90;19select * from students where name like '曹%' or chinese = 90;20select * from students where name like '曹%' || chinese = 90;
2.3.2 Distinct
使用
DISTINCT对数据表中一个或多个字段重复的数据进行过滤,重复的数据只返回其一条数据给用户.xxxxxxxxxx51SELECT DISTINCT <字段名> FROM <表名>;2eg:4select distinct chinese from students;5select distinct chinese, english from students;注意:
xxxxxxxxxx31-- DISTINCT 只能在SELECT语句中使用。 (对结果进行去重)2-- 当对一个或多个字段去重时,DISTINCT 要写在所有字段的最前面。3-- 如果 DISTINCT 对多个字段去重时,只有多个字段组合起来完全是一样的情况下才会被去重。
2.3.3 Limit
使用
LIMIT对数据表查询结果集大小进行限定.xxxxxxxxxx81SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目2SELECT <查询内容|列等> FROM <表名字> LIMIT 初始位置,记录数目;3SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目 OFFSET 初始位置;4eg:6select * from students limit 3;7select * from students limit 4, 3;8select * from students limit 3 offset 4;LIMIT 记录数目: 从第一条开始, 限定记录数目
LIMIT 初始位置,记录数目: 从起始位置开始, 限定记录数目
LIMIT 记录数目 OFFSET 初始位置: 从起始位置开始, 限定记录数目
注意: 数据(默认下标从0开始)
2.3.4 As
AS关键字用来为表和字段指定别名.xxxxxxxxxx111<内容> AS <别名>2eg:4select name from students;5select * from students as s where s.chinese < 60;6select s.name from students as s ;7select s.name from students as s where s.chinese < 60;8select name as username from students;9select * from students;10select *, (chinese + english + math) from students;11select *, (chinese + english + math) as sum from students;
2.3.5 Order By
ORDER BY对查询数据结果集进行排序.xxxxxxxxxx81SELECT <查询内容|列等> FROM <表名字> ORDER BY <字段名> [ASC|DESC];2eg:4select * from students order by chinese;5select * from students order by chinese asc;6select * from students order by chinese desc;7select * from students order by chinese, english;8select * from students order by chinese desc, english desc, math desc;不加排序模式: 升序排序.
ASC: 升序排序.
DESC: 降序排序.
注意: 如上查询, 当我们进行多字段排序的时候, 会先满足第一个列的排序要求, 如果第一列一致的话, 再按照第二列进行排序, 以此类推.
2.3.6 Group By
使用 GROUP BY 关键字,对数据进行分组
xxxxxxxxxx91SELECT <查询内容|列等> FROM <表名字> GROUP BY <字段名...>2eg:4select class, group_concat(name), group_concat(chinese) from students group by class;5select class, group_concat(name) from students where chinese > 90 group by class;6select class, group_concat(name), avg(chinese) from students group by class;8select class, group_concat(name) from students group by class having count(*) > 3;9select class, group_concat(name), avg(chinese) from students group by class having avg(chinese) > 60;GROUP_CONCAT()函数会把每个分组的字段值都显示出来.
HAVING 可以让我们对分组后的各组数据过滤。(一般和分组+聚合函数配合使用)
2.3.7 聚合函数
聚合函数一般用来计算列相关的指定值.
通常和分组一起使用
函数 作用 函数 作用 COUNT 计数 SUM 和 AVG 平均值 MAX 最大值 MIN 最小值
COUNT: 计数
xxxxxxxxxx71SELECT <查询内容|列等> , COUNT <列|*> FROM <表名字> GROUP BY HAVING COUNT <表达式|条件>23eg:4select count(*) from students5select count(name) from students6select class, group_concat(name), count(*) from students group by class;7select class, group_concat(name), count(*) from students group by class having count(*) > 2;COUNT(*): 表示表中总行数
COUNT(列): 计算除了列值为NULL以外的总行数
SUM: 求和
xxxxxxxxxx101SELECT <查询内容|列等> , SUM<列> FROM <表名字> GROUP BY HAVING SUM<表达式|条件>23eg:4select sum(chinese) from students;5select sum(chinese), sum(english), sum(math) from students;6select class, group_concat(name), sum(chinese) from students group by class;7select class, group_concat(name), sum(chinese) from students group by class having sum(chinese)>200;8select class, group_concat(name), sum(chinese), sum(math) from students group by class;9select class, group_concat(name), sum(chinese), sum(math) from students group by class having sum(chinese)>200 and sum(math) > 200;10AVG: 平均值
xxxxxxxxxx91SELECT <查询内容|列等> , AVG<列> FROM <表名字> GROUP BY HAVING AVG<表达式|条件>23eg:4select avg(chinese) from students;5select avg(chinese), avg(english), avg(math) from students;6select class, group_concat(name), avg(chinese) from students group by class;7select class, group_concat(name), avg(chinese) from students group by class having avg(chinese)>=60;8select class, group_concat(name), avg(chinese), avg(math) from students group by class;9select class, group_concat(name), avg(chinese), avg(math) from students group by class having avg(chinese)>=60 and avg(math) >=60;MAX: 最大值
xxxxxxxxxx91SELECT <查询内容|列等> , MAX<列> FROM <表名字> GROUP BY HAVING MAX<表达式|条件>23eg:4select max(chinese) from students;5select max(chinese), max(english), max(math) from students;6select class, group_concat(name), max(chinese) from students group by class;7select class, group_concat(name), max(chinese) from students group by class having max(chinese)>90;8select class, group_concat(name), max(chinese), max(math) from students group by class;9select class, group_concat(name), max(chinese), max(math) from students group by class having max(chinese)>=90 and max(math) >=70;MIN: 最小值
xxxxxxxxxx91SELECT <查询内容|列等> , MIN<列> FROM <表名字> GROUP BY HAVING MIN<表达式|条件>23eg:4select min(chinese) from students;5select min(chinese), min(english), max(math) from students;6select class, group_concat(name), min(chinese) from students group by class;7select class, group_concat(name), min(chinese) from students group by class having min(chinese)>60;8select class, group_concat(name), min(chinese), min(math) from students group by class;9select class, group_concat(name), min(chinese), min(math) from students group by class having min(chinese)>=60 and min(math) >=60;
2.4 SQL执行顺序
xxxxxxxxxx111(5) SELECT column_name, ...2(1) FROM table_name, ...3(2) [WHERE ...]4(3) [GROUP BY ...]5(4) [HAVING ...]6(6) [ORDER BY ...];7(7) [Limit ...]8-- 计算每个班级中语文成绩大于60的同学的平均数学成绩, 获得平均数学成绩大于等于40的班级中平均语文成绩最高的那个班级的平均语文和数学成绩10eg:11select class, group_concat(name), avg(chinese) as chineseA, avg(math) from students where chinese >= 60 group by class having avg(math)>=40 order by chineseA desc limit 0, 1;
小括号中的数字代表执行顺序
having和select的执行顺序收到优化器的影响,可能会改变执行顺序
2.5 数据完整性
为了在
实际工程环境中更好的使用和维护数据库数据, 在我们设计和使用数据库的库/表/数据的时候, 一般要遵循数据完整性规则;数据完整保证在数据库设计和数据存储过程中, 对数据的存储/处理是做到尽可能正确; 做到降低用户在实际使用的时候出错的可能性, 尽可能提高数据库的使用效率.
ps: 所谓数据完整性: 是在数据库中表和数据的设计的时候定制的一些约定俗成的参考规范. 是站在组织数据的角度, 目的是希望在数据库中数据存储更规整,以及希望操作数据的时候效率更高
而
数据完整性又包含: 实体完整性; 域完整性; 参照完整性
2.5.1 实体完整性
保证
表中的每一行数据都是表中唯一的实体.(即:一个表中每一条数据都应该是唯一的)实体完整性是为了保证表中
数据唯一, 实体完全可由主键实现(通过一个主键的设置, 保证一个表中每一条信息都是唯一的).xxxxxxxxxx81CREATE TABLE `students` (2`id` int(11) PRIMARY KEY AUTO_INCREMENT,3`name` varchar(255) ,4`class` varchar(255) ,5`chinese` float ,6`english` float ,7`math` float8) ;
2.5.2 域完整性
域完整性表示保证表中数据的字段的取值在有效范围之内或者符合特定的数据类型约束1, 含义: 某一列的数据存储的类型要设计合适 (
float,varchar,NULL,NOT NULL...)2, 在某一列存储数据的时候, 存储的数据的内容, 应该要符合对这个列的类型以及大小限定
xxxxxxxxxx81CREATE TABLE `students` (2`id` int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,3`name` varchar(10) NOT NULL DEFAULT "张飞",4`class` varchar(5) NULL DEFAULT NULL,5`chinese` float NOT NULL,6`english` float NOT NULL,7`math` float NOT NULL8);
2.5.3 参照完整性
参照完整性用于确保相关联的表间的数据应该要保持一致.避免因为一个表的数据/记录修改, 造成另一个表的内容变为无效的值. 一般来讲, 参照完整性是通过外键和主键来维护的.
外键是参照完整性的一种强有力的维护手段.
参照完整性 != 外键
主键的设置和取消: (了解)
xxxxxxxxxx381--方式一: 在创建表的时候设置外键2CREATE TABLE `class` (3`id` int NOT NULL PRIMARY KEY,4`name` varchar(20) NULL5);6CREATE TABLE `student` (7`id` int NOT NULL PRIMARY KEY,8`name` varchar(20) NULL,9`class_id` int ,10CONSTRAINT `foreign_key_name` FOREIGN KEY (class_id) REFERENCES `class`(`id`)11);12--方式二: 表创建完毕, 对表设置外键13CREATE TABLE `class` (14`id` int NOT NULL PRIMARY KEY,15`name` varchar(20) NULL16);17CREATE TABLE `student` (18`id` int NOT NULL PRIMARY KEY,19`name` varchar(20) NULL,20`class_id` int21);22ALTER TABLE `student` ADD CONSTRAINT `foreign_key_name` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`);24--方式三: 表创建完毕, 添加新的字段列, 并且设置为外键26CREATE TABLE `class` (27`id` int NOT NULL PRIMARY KEY,28`name` varchar(20) NULL29);30CREATE TABLE `student` (31`id` int NOT NULL PRIMARY KEY,32`name` varchar(20) NULL33);34alter table `student` add column `class_id` int null after `name`,35add constraint `foreign_key_name` foreign key (`class_id`) references `class` (`id`);36-- 删除外键38ALTER TABLE `student` DROP FOREIGN KEY `foreign_key_name`;外键优缺点: 重要
xxxxxxxxxx71优点:2// 能够限制数据的增加、删除或者是修改操作,来保证数据的一致性。3缺点:4// 在插入/修改子表(student)的数据的时候,需要去父表(class)中找对应的数据5// 在删除/修改父表(class)的数据的时候,需要去检查子表(student)中是否有对应的数据6// 有了外键之后,影响了增加、删除、修改的性能7// 使用起来也不方便在公司中是否使用外键呢: 重要
xxxxxxxxxx51看具体公司内部的情况是否使用外键2// 假如公司表中的数据量不大(外键对效率的影响比较小,甚至可以忽略),可以考虑使用外键3// 假如公司数据库表中的数据很多,(外键对于效率的影响就会很大),不应该使用外键4// 人为使用习惯(内心OS)5// ...
3, SQL和多表问题
数据基础
xxxxxxxxxx401-- 班级2CREATE TABLE `class` (3`id` int(11) NOT NULL,4`class_name` varchar(10) ,5PRIMARY KEY (`id`)6);7-- 成绩8CREATE TABLE `score` (9`id` int(11) NOT NULL AUTO_INCREMENT,10`student_id` int(11) ,11`class_id` int(11),12`chinese` float ,13`english` float ,14`math` float ,15PRIMARY KEY (`id`)16);17-- 学生信息18CREATE TABLE `student` (19`id` int(11) NOT NULL,20`student_name` varchar(20),21`nick_name` varchar(20) ,22`mobile` varchar(20) ,23`era` varchar(20),24`motto` varchar(30),25PRIMARY KEY (`id`)26);27-- 剧本28CREATE TABLE `script` (29`id` int(11) NOT NULL,30`play_name` varchar(20),31`play_ location` varchar(20) ,32PRIMARY KEY (`id`)33);34-- 演出表35CREATE TABLE `show` (36`id` int(11) NOT NULL,37`student_id` int(11),38`script_id` int(11),39PRIMARY KEY (`id`)40);xxxxxxxxxx591-- ----------------------------2INSERT INTO `class` VALUES (1, '一班');3INSERT INTO `class` VALUES (2, '二班');4INSERT INTO `class` VALUES (3, '三班');5INSERT INTO `class` VALUES (4, '四班');6INSERT INTO `class` VALUES (5, '五班');7-- ----------------------------8INSERT INTO `score` VALUES (1, 1, 1, 70, 90, 60);9INSERT INTO `score` VALUES (2, 2, 1, 70, 90, 90);10INSERT INTO `score` VALUES (3, 3, 1, 90, 90, 20);11INSERT INTO `score` VALUES (4, 4, 2, 60, 60, 60);12INSERT INTO `score` VALUES (5, 5, 2, 95, 80, 5);13INSERT INTO `score` VALUES (6, 6, 2, 25, 25, 5);14INSERT INTO `score` VALUES (7, 7, 3, 90, 90, 90);15INSERT INTO `score` VALUES (8, 8, 3, 90, 80, 80);16INSERT INTO `score` VALUES (9, 9, 3, 98, 90, 80);17INSERT INTO `score` VALUES (10, 10, 3, 95, 90, 80);18INSERT INTO `score` VALUES (11, 11, 3, 98, 95, 95);19INSERT INTO `score` VALUES (12, 12, 3, 80, 90, 80);20-- ----------------------------21INSERT INTO `script` VALUES (1, '三打祝家庄', '祝家庄');22INSERT INTO `script` VALUES (2, '梁山聚义', '梁山');23INSERT INTO `script` VALUES (3, '壮士落幕', '六和寺');24INSERT INTO `script` VALUES (4, '赤壁之战', '赤壁');25INSERT INTO `script` VALUES (5, '七步诗事件', '洛阳');26INSERT INTO `script` VALUES (6, '白帝城托孤', '白帝城');27INSERT INTO `script` VALUES (7, '煮酒论英雄', '许昌');28-- ----------------------------29INSERT INTO `show` VALUES (1, 1, 1);30INSERT INTO `show` VALUES (2, 2, 1);31INSERT INTO `show` VALUES (3, 3, 1);32INSERT INTO `show` VALUES (4, 1, 2);33INSERT INTO `show` VALUES (5, 2, 2);34INSERT INTO `show` VALUES (6, 3, 2);35INSERT INTO `show` VALUES (7, 1, 3);36INSERT INTO `show` VALUES (8, 2, 3);37INSERT INTO `show` VALUES (9, 7, 4);38INSERT INTO `show` VALUES (10, 10, 4);39INSERT INTO `show` VALUES (11, 11, 4);40INSERT INTO `show` VALUES (12, 12, 4);41INSERT INTO `show` VALUES (13, 8, 5);42INSERT INTO `show` VALUES (14, 9, 5);43INSERT INTO `show` VALUES (15, 11, 6);44INSERT INTO `show` VALUES (16, 12, 6);45INSERT INTO `show` VALUES (17, 7, 7);46INSERT INTO `show` VALUES (18, 11, 7);47-- ----------------------------48INSERT INTO `student` VALUES (1, '武松', '行者', '13440996665', '宋朝', '别胡说!难道不付你钱!再筛三碗来!');49INSERT INTO `student` VALUES (2, '林冲', '豹子头', '17383945041', '宋朝', '无');50INSERT INTO `student` VALUES (3, '宋江', '及时雨', '15671722818', '宋朝', '他日若遂凌云志,敢笑黄巢不丈夫');51INSERT INTO `student` VALUES (4, '贾琏', '琏二爷', '19931477852', '清朝', '无');52INSERT INTO `student` VALUES (5, '贾宝玉', '怡红公子', '13456229050', '清朝', '我要这玉又何用');53INSERT INTO `student` VALUES (6, '贾环', '孽障', '18900141462', '清朝', '无');54INSERT INTO `student` VALUES (7, '曹操', '阿满', '17273083171', '三国', '宁我负人,毋人负我');55INSERT INTO `student` VALUES (8, '曹丕', '子桓', '17180453185', '三国', '无');56INSERT INTO `student` VALUES (9, '曹植', '陈思王', '19818008917', '三国', '无');57INSERT INTO `student` VALUES (10, '孙权', '孙十万', '15638204123', '三国', '无');58INSERT INTO `student` VALUES (11, '刘备', '刘皇叔', '15638204378', '三国', '惟贤惟德,能服行人');59INSERT INTO `student` VALUES (12, '诸葛亮', '诸葛武侯,卧龙', '15119511196', '三国', '非淡泊无以明志,非宁静无以致远');
3.1 多表设计/多表理论
3.1.1 一对一
指两个表(或多个表之间)的数据存在一一对应的关系。
xxxxxxxxxx31eg:2// 用户和用户详情3// 商品和商品详情
3.1.2 一对多
指两个表(或多个表之间)的数据,存在表A中的一条数据对应表B中的多条数据,表B中的一条数据对应表A中的一条数据.
xxxxxxxxxx31eg:2// 用户和订单3// 班级和学生
3.1.3 多对多
存在两个表表A和表B,存在表A中的一条数据对应表B中的多条数据,表B中的一条数据对应表A中的多条数据。
xxxxxxxxxx51eg:2// 订单和商品3一个产品中可能有多个订单, 一个订单中可能买了多个商品4// 剧本和演员5一个演员可能出演了多个剧本, 一个剧本中可能包含多个演员
3.1.4 数据库设计范式
面试有可能问道
和数据完整性不同: 数据库的设计范式更偏向于表设计的维度来看待数据的存储. 其存在的目的也是为了, 在维护或者操作数据库中数据: 1, 希望在数据库中数据存储更规整 2, 希望操作数据的时候效率更高
第一范式: 原子性
在设计表的时候, 应该每列保持原子性。 如果数据库中的所有字段都是不可分割的原子值,则说明该数据库满足第一范式,比如:地址。
第一范式:我们在设计表的时候,应该考虑之后业务的变化,来
尽量让每一列的数据保持原子性。


第二范式: 唯一性
数据的唯一性。 要求表中数据有唯一标识,不存在部分依赖
eg: 通过主键来唯一标识一个用户(满足唯一性)
注意: 通过name+nickname+province+city+county组合标识一个用户(不满足唯一性)

第三范式: 不冗余
字段不要冗余。(消除表中非主键字段间的依赖: 即:要求每个非主键字段只依赖于主键,而不依赖于其他非主键字段)
如: 如下昵称
students表中存储了昵称
students_detail表中也存储了昵称


3.2 多表查询
查询的结果是一个新的临时表。
数据基础
xxxxxxxxxx61-- 装备表2CREATE TABLE `equip` (3`id` int(11) NOT NULL PRIMARY KEY,4`student_id` int(11) NULL DEFAULT NULL,5`equip_name` varchar(255) NULL DEFAULT NULL6) ;xxxxxxxxxx101INSERT INTO `equip` VALUES (1, 1, '行者套账');2INSERT INTO `equip` VALUES (2, 2, '丈八蛇矛');3INSERT INTO `equip` VALUES (3, 5, '通灵宝玉');4INSERT INTO `equip` VALUES (4, 7, '七星刀');5INSERT INTO `equip` VALUES (5, 7, '绝影马');6INSERT INTO `equip` VALUES (6, 7, '爪黄飞电马');7INSERT INTO `equip` VALUES (7, 7, '倚天剑');8INSERT INTO `equip` VALUES (8, 7, '青釭剑');9INSERT INTO `equip` VALUES (9, 11, '的卢马');10INSERT INTO `equip` VALUES (10, 11, '双股剑');
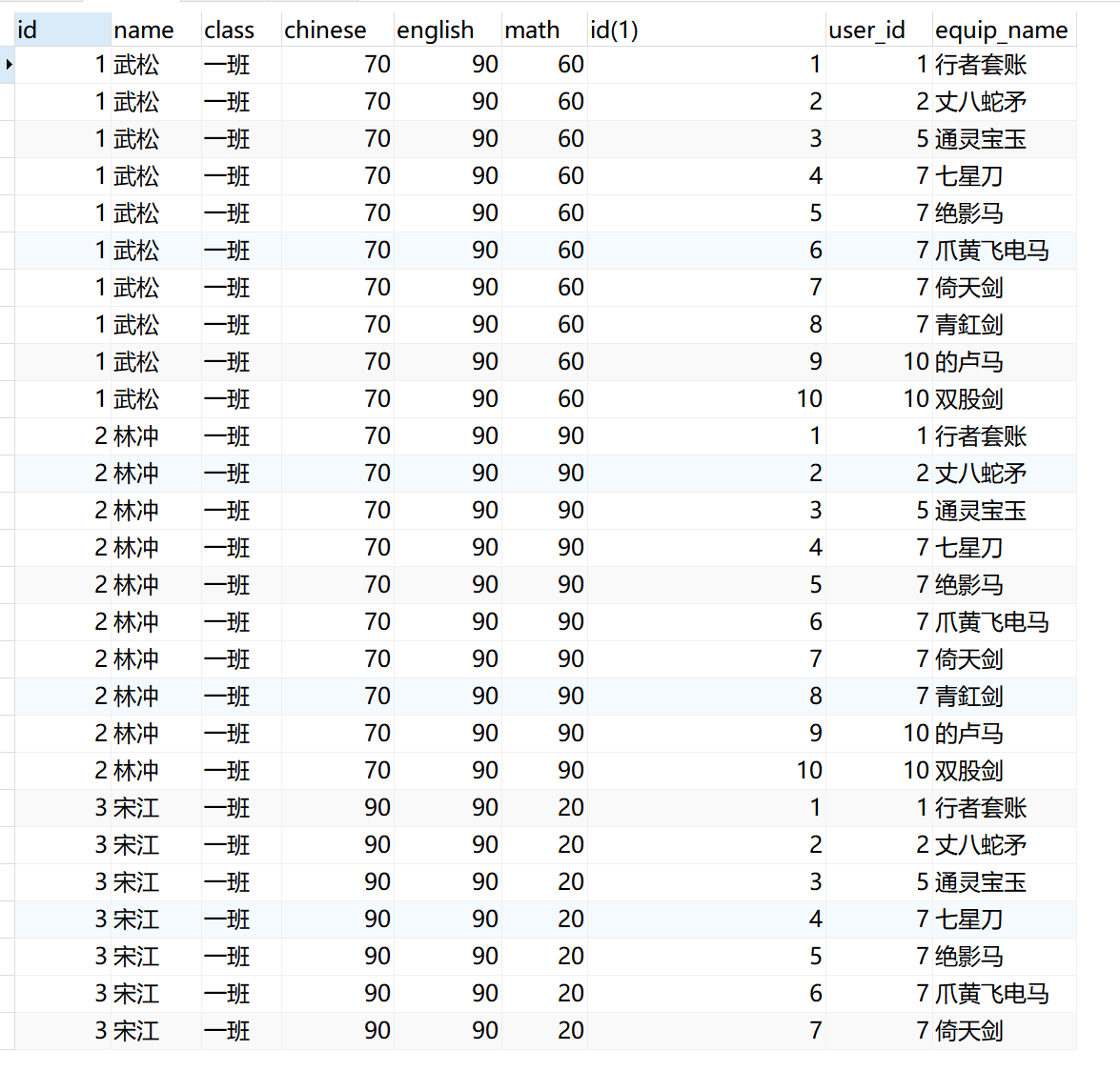
xxxxxxxxxx81select2sd.student_name, c.class_name, s.chinese , group_concat(e.equip_name)3from student sd4inner join score s on sd.id = s.student_id5inner join class c on c.id = s.class_id6inner join equip e on e.student_id = sd.id7where sd.student_name = "曹操"8group by sd.student_name, c.class_name, s.chinese ;
3.2.1 链接/连接查询
交叉链接
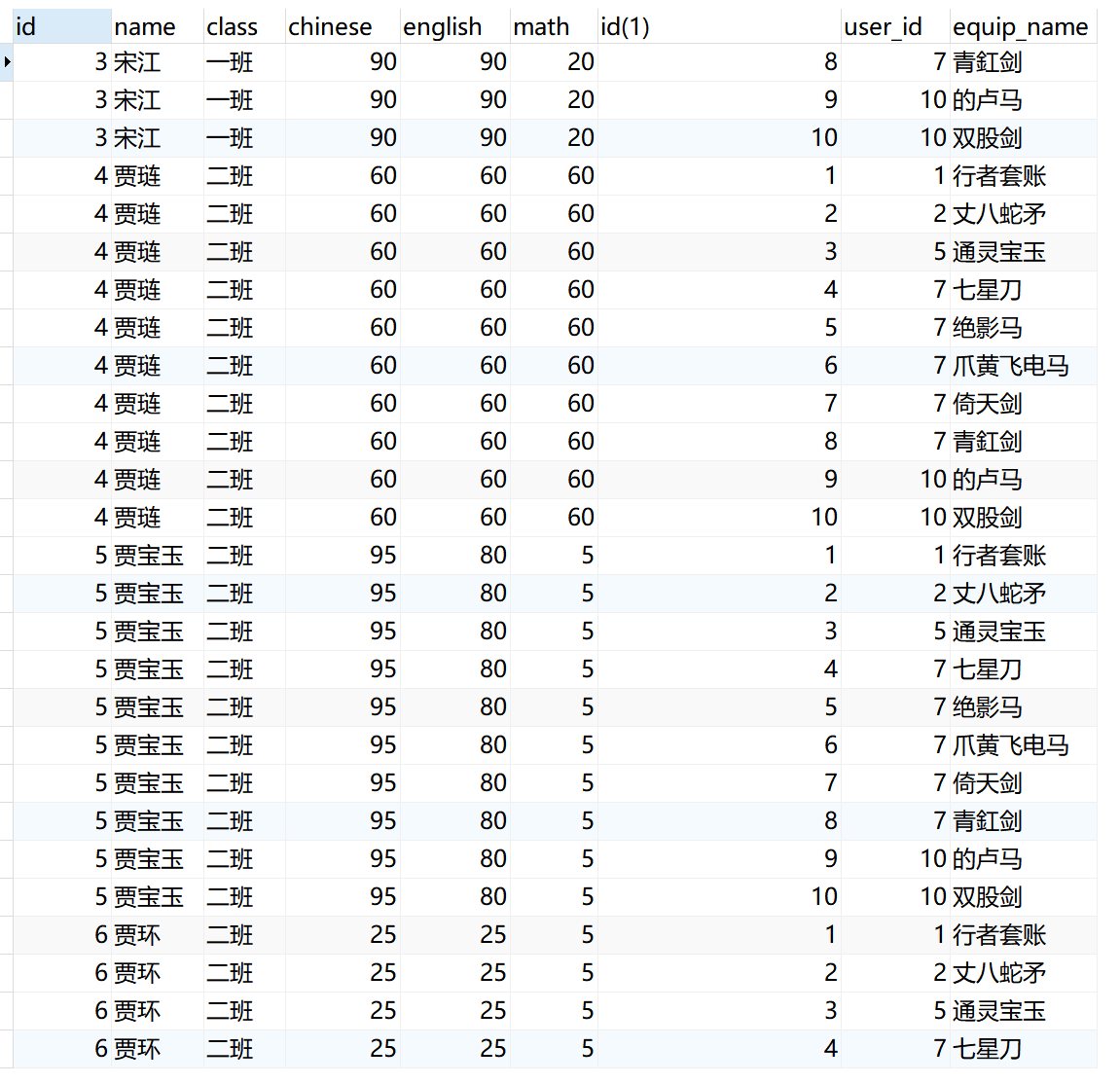
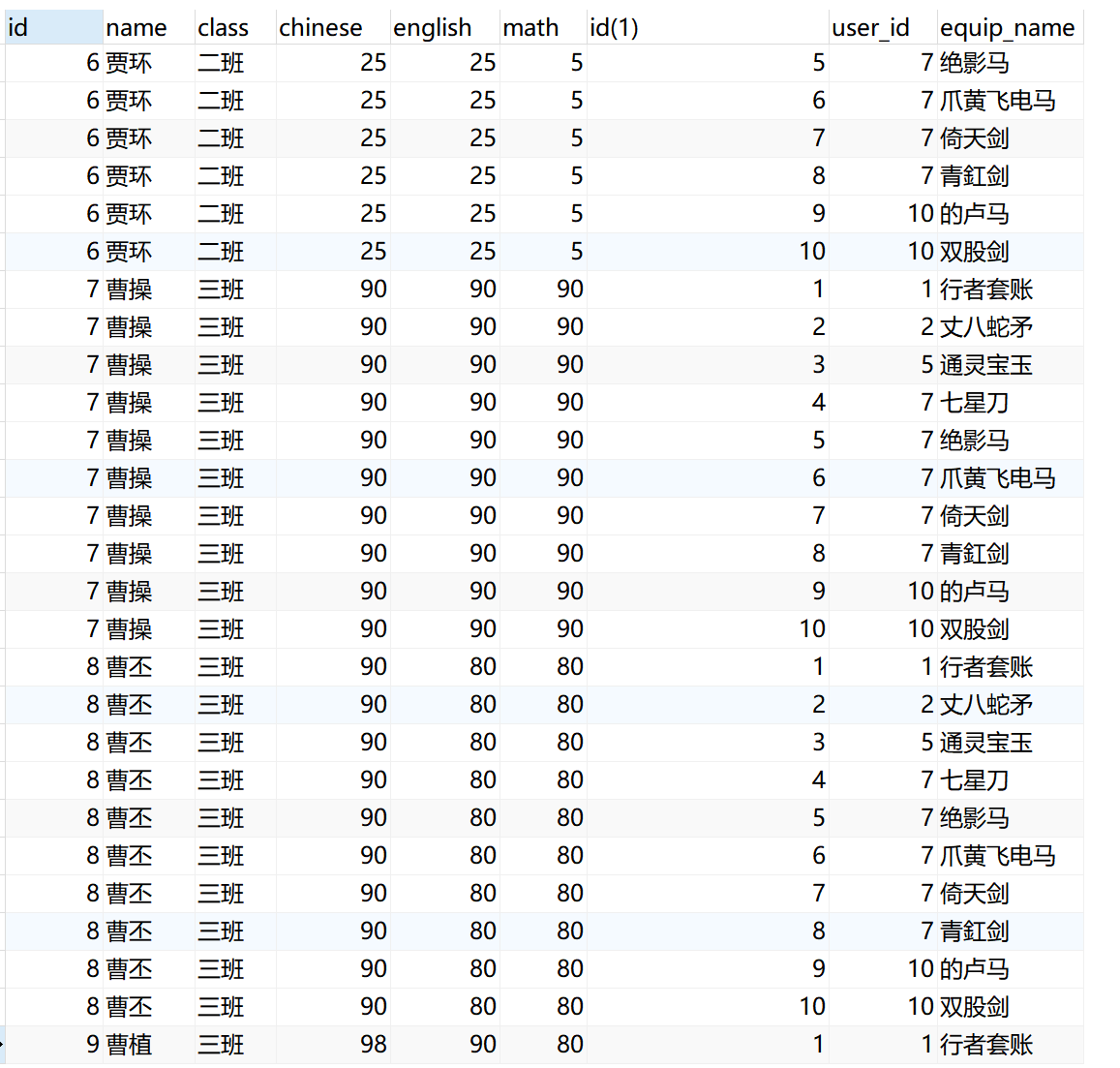
交叉连接其实就是求多个表的笛卡尔积。xxxxxxxxxx81SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句]2eg:5select * from student cross join equip;6select * from student cross join equip where student.id = equip.student_id;7-- 两个表的笛卡尔积,返回结果数量就是两个表的数据行相乘。8-- 如果每个表有1000行,那么返回结果的数量就有1000×1000=1000000行。仅
交叉连接的结果没有太多实际的使用意义。
自然连接
自然连接: 没什么用xxxxxxxxxx51-- 自然连接是基于两个表之间的共同列来自动匹配并组合数据。2-- 自然连接将结果集限制为只包括两个表中`具有相同值`的列(并且在结果集中把重复的列去掉)。在使用自然连接时,不需要指定连接条件,而是根据两个表中具有相同名称和数据类型的列进行匹配。 (注意: 有些数据库不支持自然连接, 比如SQLServer )3eg:5select * from student natural join class
内连接
内连接: 比较常用xxxxxxxxxx71SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]2eg:4-- 显示内连接5select * from student inner join equip on student.id = equip.student_id;6-- 隐式内连接: 不建议这样写(这是早期的sql语法中内连接的一种写法)7select * from student , equip where student.id = equip.student_id;
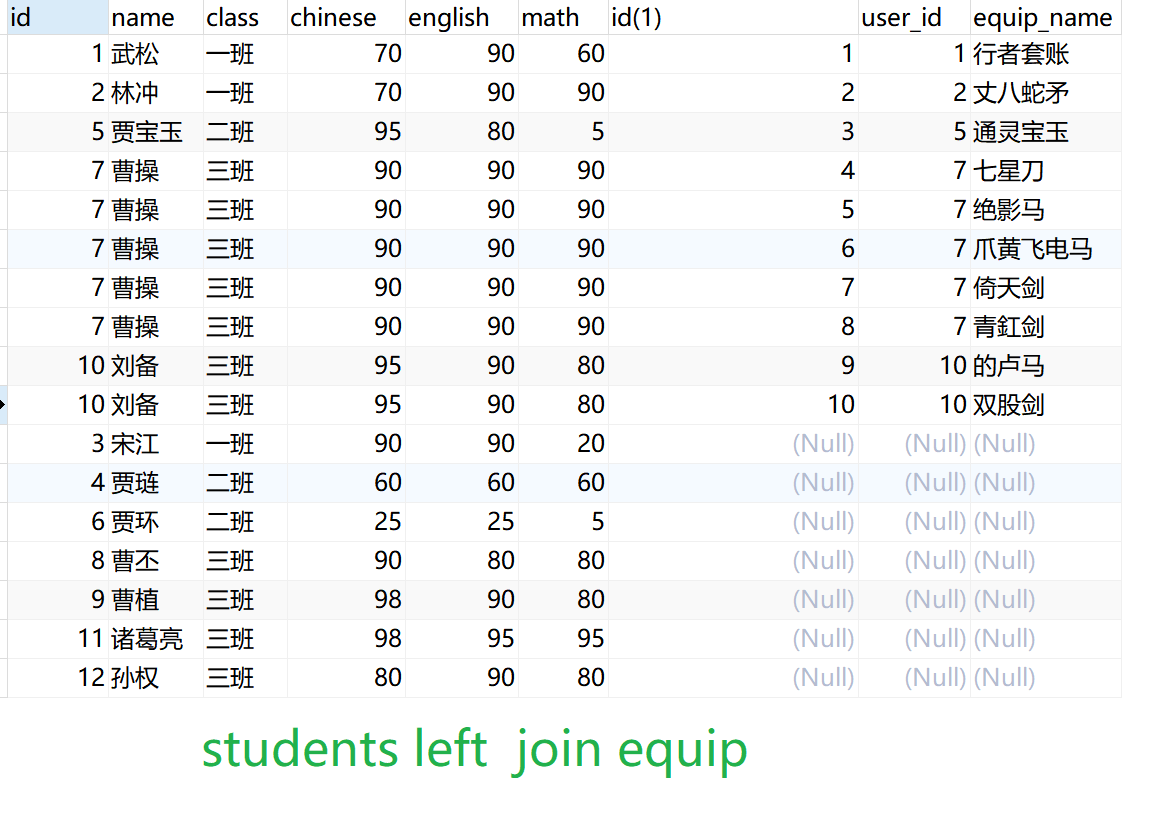
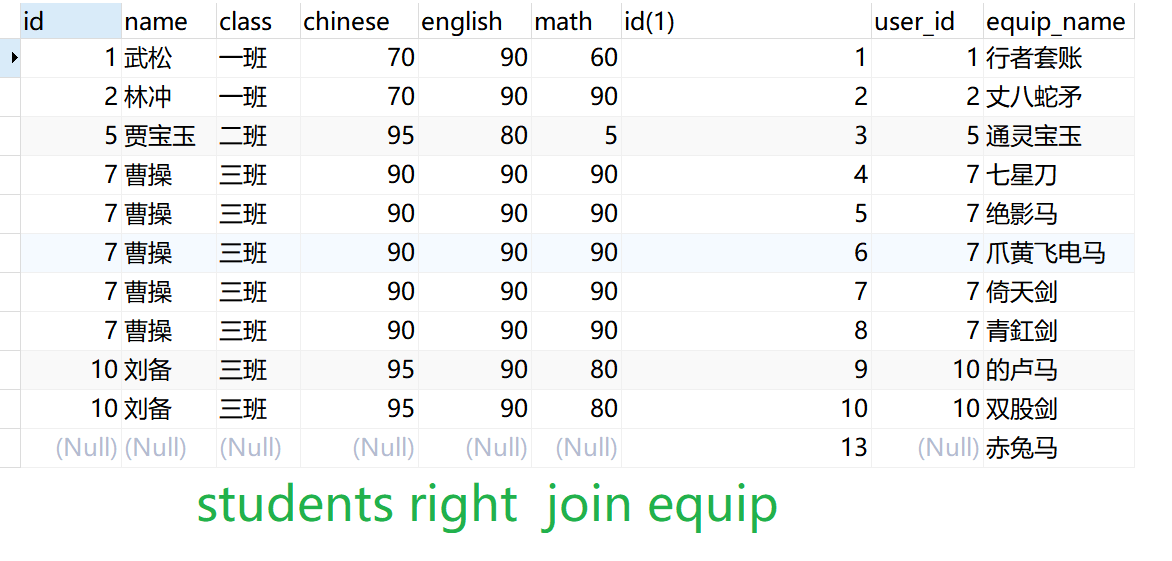
外连接: 左右外连接
外连接xxxxxxxxxx111SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2> <ON子句>2SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2> <ON子句>3eg:5select * from student left outer join equip on student.id = equip.student_id;6select * from student right outer join equip on student.id = equip.student_id;7select * from equip right outer join student on student.id = equip.student_id;8select * from equip left outer join student on student.id = equip.student_id;9-- outer可省略: 工作中多数人省略了outer10select * from student left join equip on student.id = equip.student_id;11select * from student right join equip on student.id = equip.student_id;
注: 主副表的问题
假设A和B表进行连接,AB两张表一个表示主表,另一个是副表; 查询数据的时候, 以主表中的数据为基准,匹配副表对应的数据; 当副表中的数据没有能和主表对应数据相互匹配的数据,副表匹配位置自动填充null。
自连接
自连接xxxxxxxxxx51-- 自连接是指在同一个表中,使用不同的别名将它们连接到一起。2eg:4-- 查询数学成绩低于林冲的数学成绩的人的信息5select t1.* from score t1,score t2 where t2.id = 1 and t1.chinese < t2.chinese
3.2.2 子查询
子查询也叫嵌套查询.( 在某个操作中(删除/修改/查找), 用到了另外一个查询的结果. )
是指在WHERE子句或FROM子句中又嵌入SELECT查询语句.
xxxxxxxxxx101SELECT <字段名> FROM <表|子查询> WHERE <IN| NOT IN | EXISTS | NOT EXISTS > <子查询>2eg:4select * from student where id in (select student_id from equip);5select * from student where id not in (select student_id from equip where student_id != "");6select * from student where exists (select * from equip where student_id = 11);8select * from student where not exists (select * from equip where student_id = 11);9select * from student where exists (select * from equip where student_id = 11) and id = 5;10-- 在MySQL每次查询数据的结果集都是一个新的临时表。
3.2.3 联合查询
联合查询合并两条查询语句的查询结果.
联合查询去掉两条查询语句中的重复数据行,然后返合并后没有重复数据行的查询结果。xxxxxxxxxx41SELECT <字段名> FROM <表> UNION SELECT <字段名> FROM <表>2eg:4select * from score where chinese >= 90 union select * from score where math >= 90;
4, 数据库备份和恢复
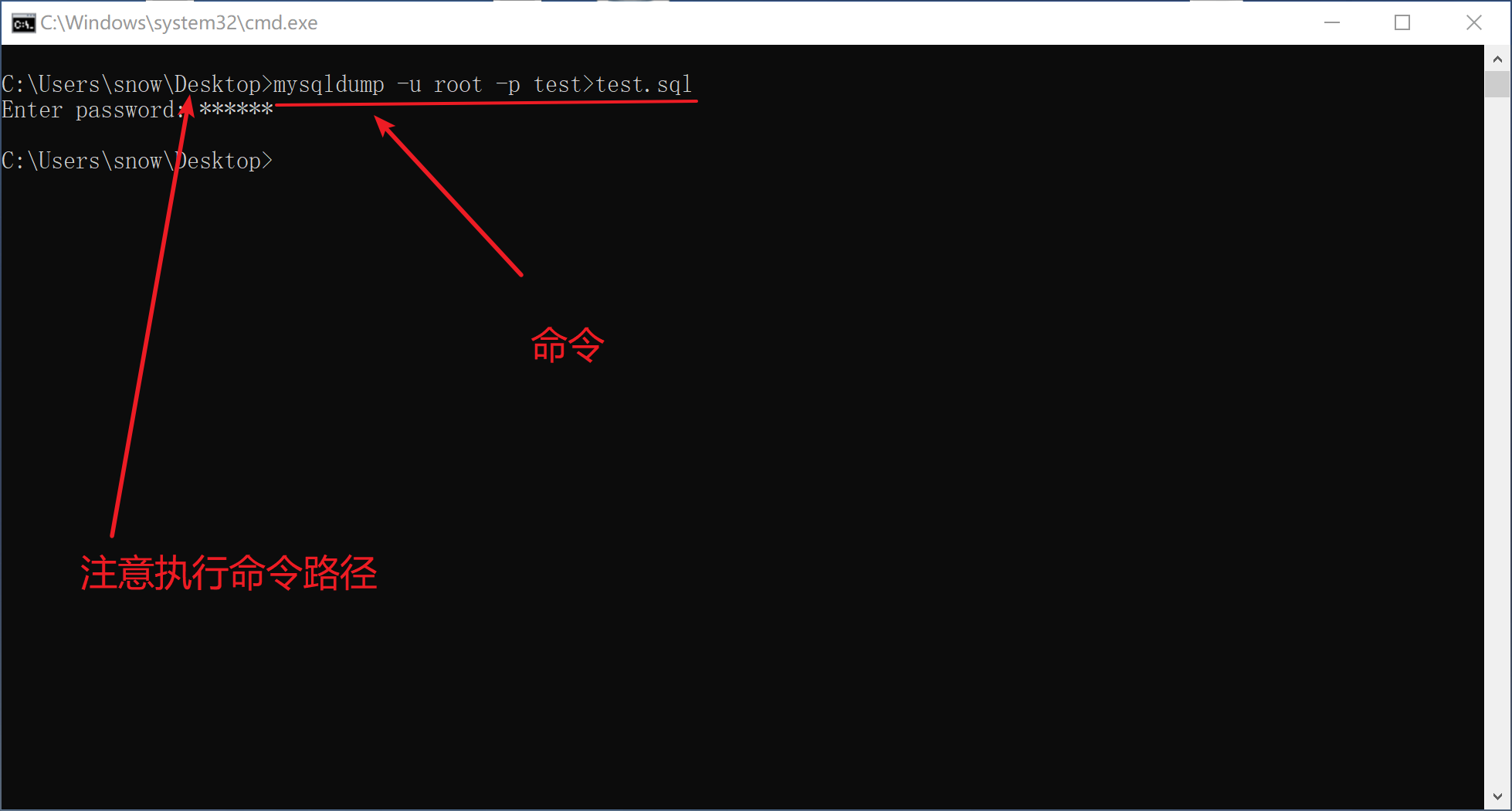
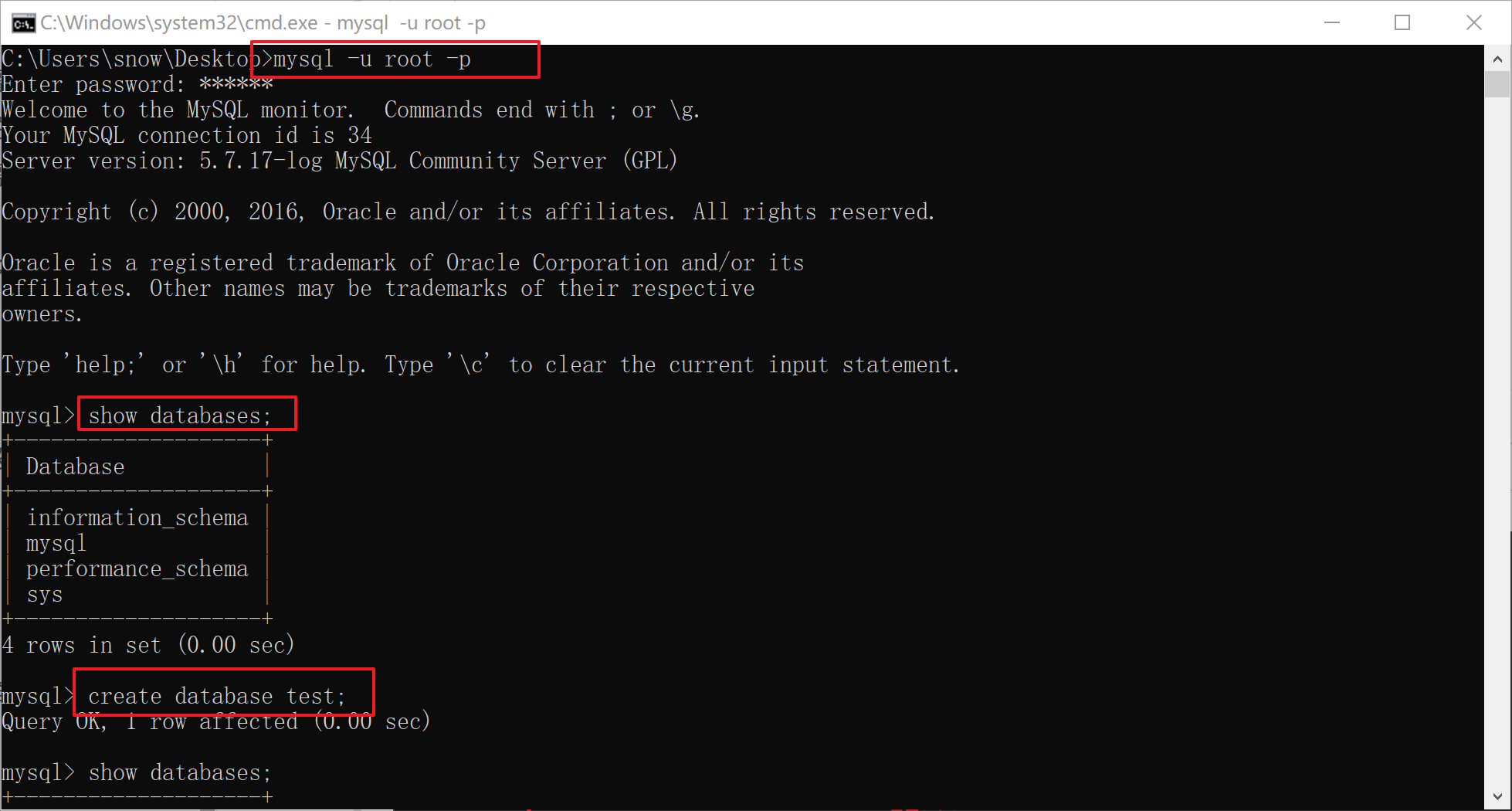
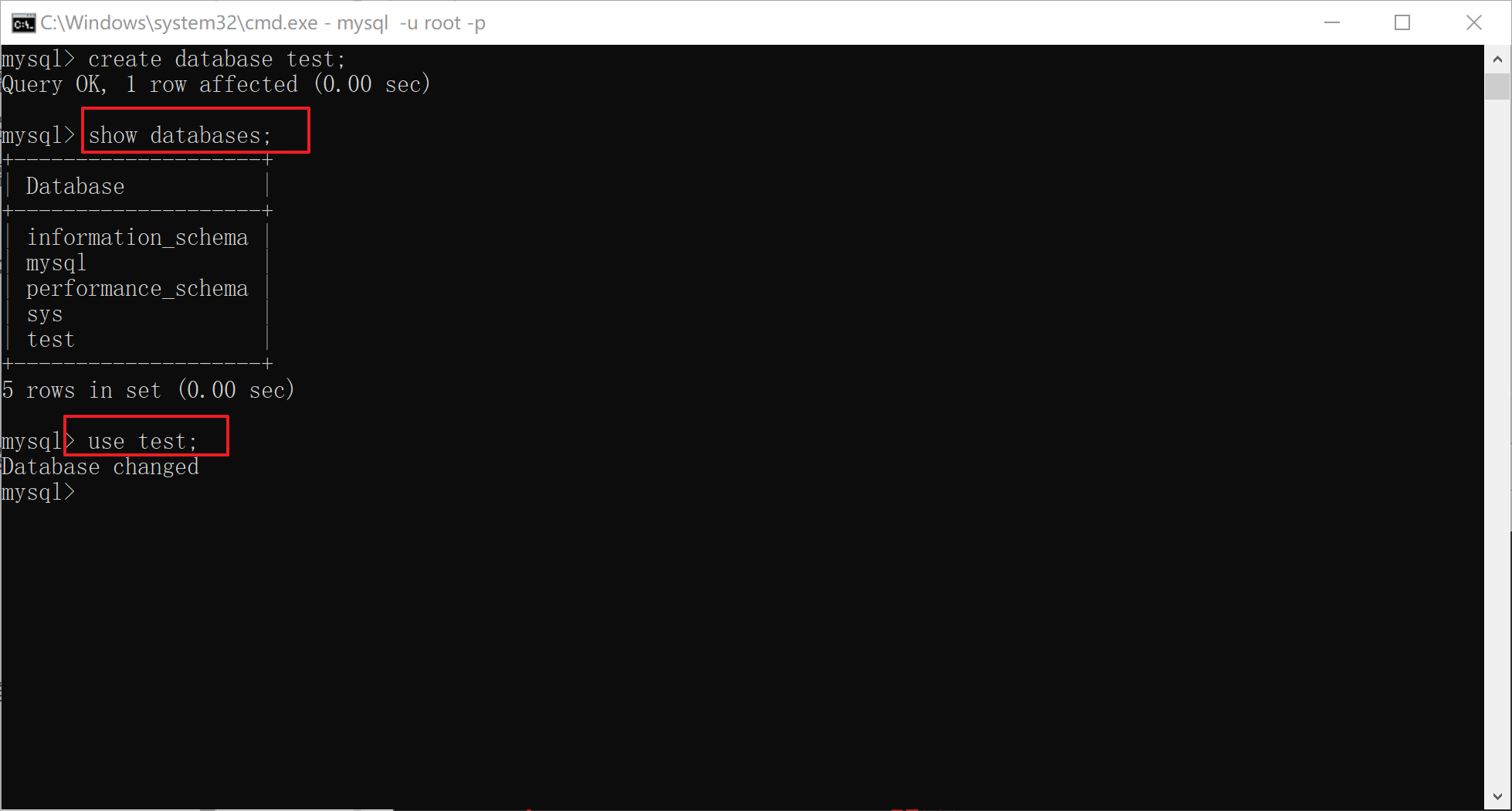
4.1 命令行操
通过命令行操作
xxxxxxxxxx101-- 数据库备份:cmd命令下2mysqldump -u root -p 数据库名称>文件名.sql3-- 数据库恢复:5-- 1. 创建数据库并选择该数据库6create database dbName;7use dbName;8-- 2. 恢复数据9source 文件名.sql10备份:
恢复:

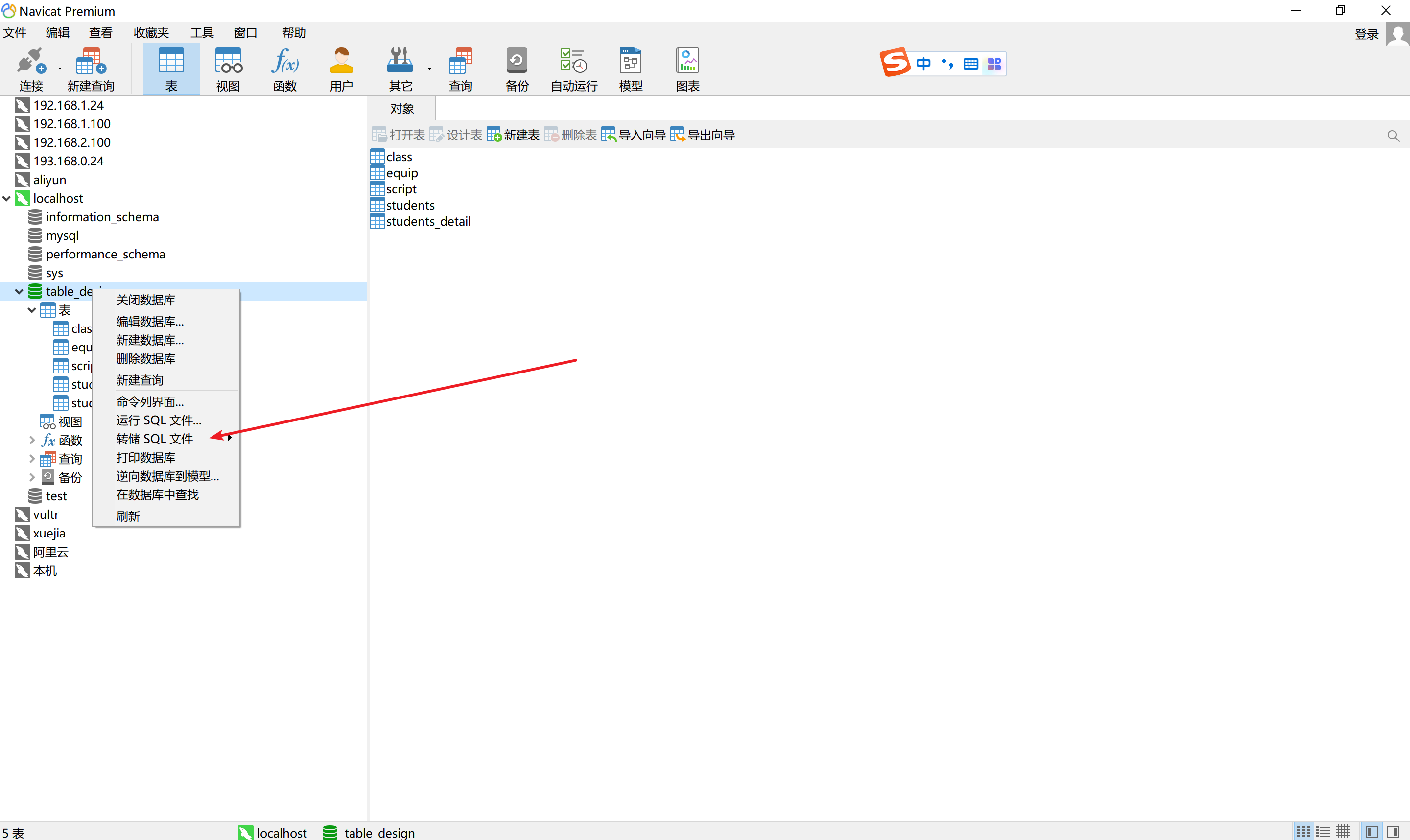
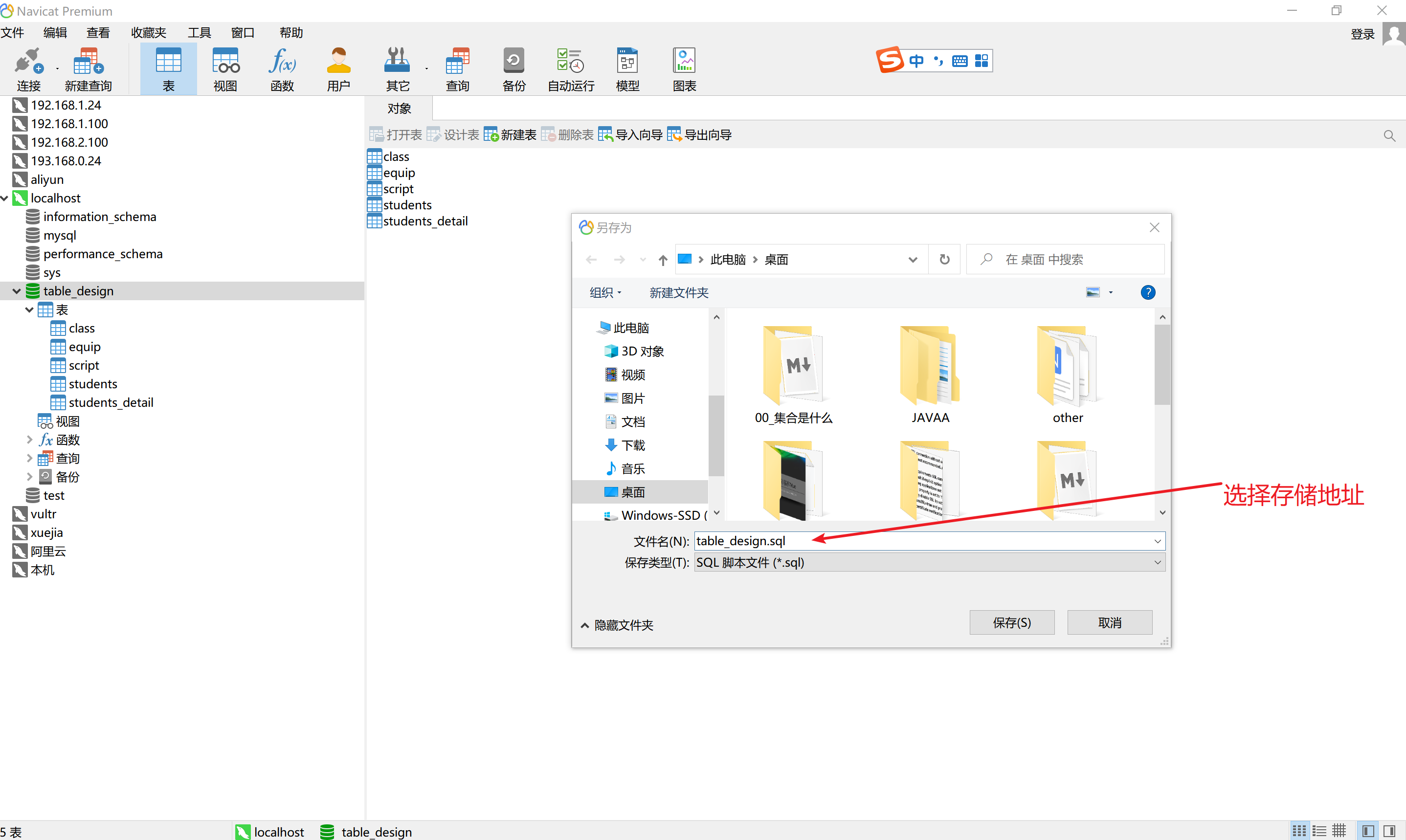
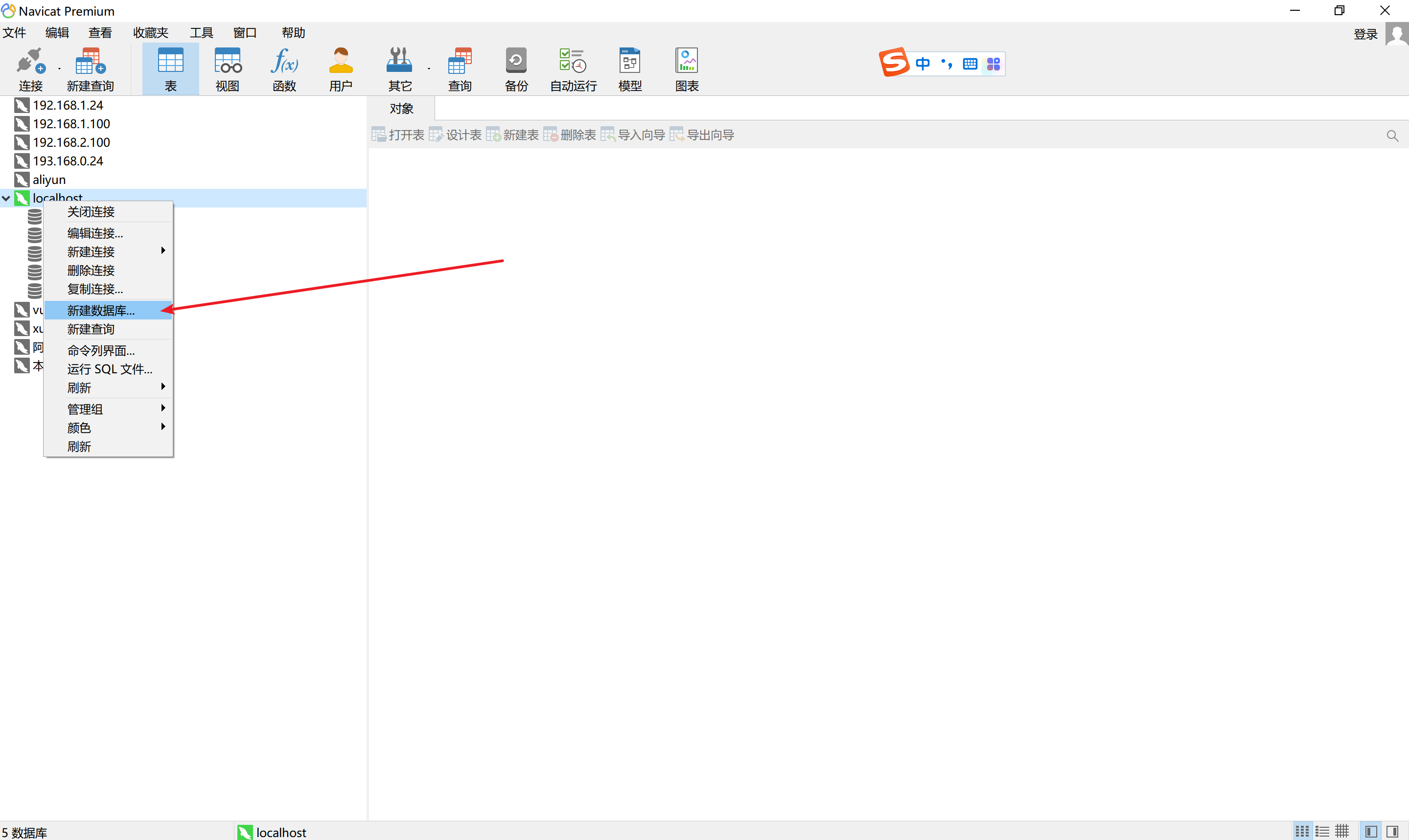
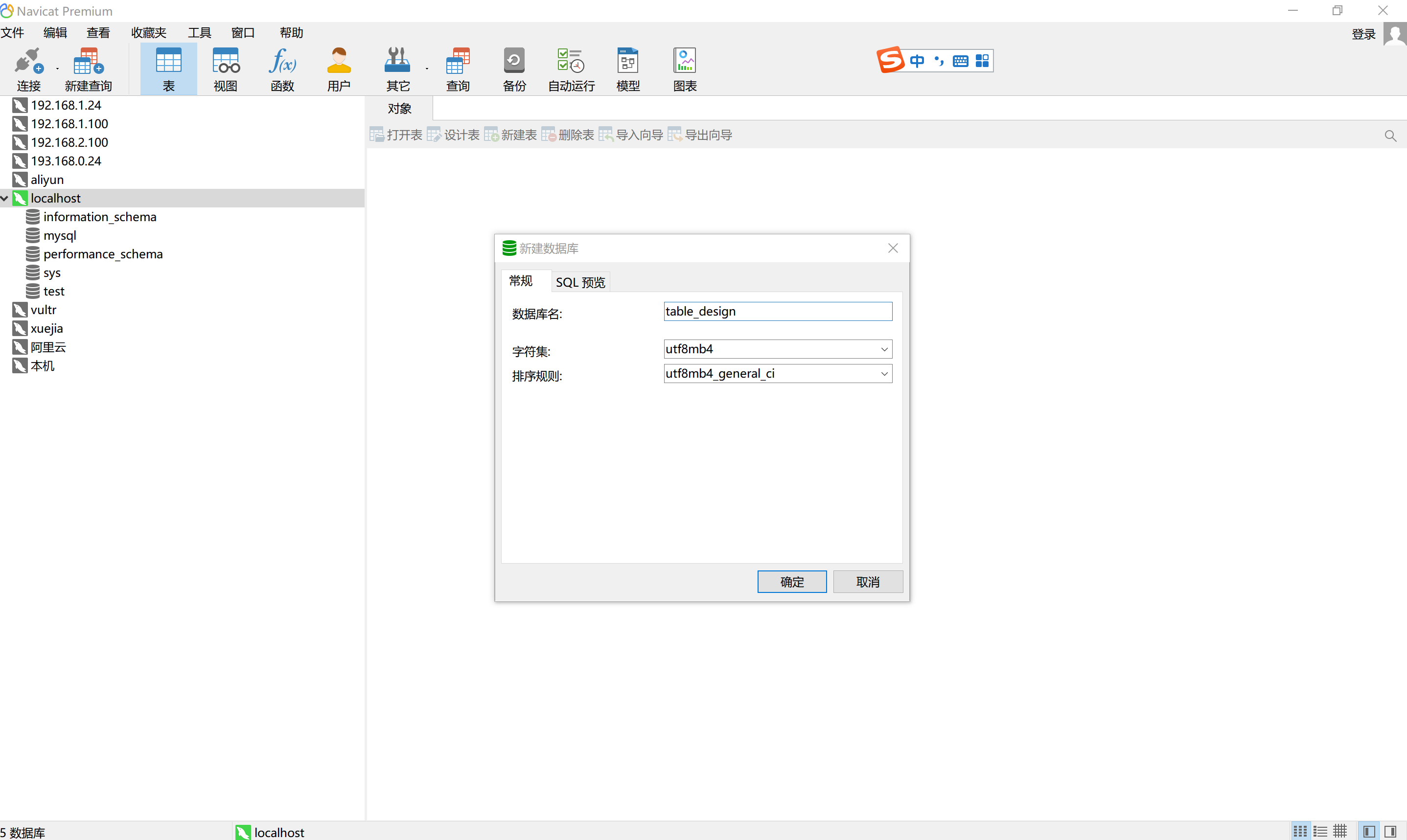
4.2 图形化界面
以Navicat为例
备份:
导入:
5, 上课sql
7月2号的sql
xxxxxxxxxx2181CREATE TABLE `students` (2`id` int(11) PRIMARY KEY AUTO_INCREMENT,3`name` varchar(255) ,4`class` varchar(255) ,5`chinese` float ,6`english` float ,7`math` float8) ;9/* 注释 */11-- 注释12# 注释13show tables;14-- 查询表中有哪些信息16select * from students;17-- 添加数据20-- insert into 表名 (列1, 列2, 列3...) values (值1, 值2, 值3 ....)21insert into students (id, name, class, chinese, english, math)22values (1, 'zs', '一班', 90, 90, 95);23insert into students (id, class, name, chinese, english, math)25values (2, '一班','ls', 90, 90, 95);26insert into students (id, name ) values (3, "wu");28insert into students (id, name) values(NULL, "zl");29-- 添加数据的时候, 省略列, 直接写values, 要求values的值和表中的列要一一对应31insert into students values( NULL, "sq", NULL, 97, 97, 5);32-- 添加数据, 使用set的写法: set 列1=值1, 列2=值2 ....34insert into students set id = 6, name='a', class='二班' ;35-- 添加多条数据(批量添加): b, c, d37insert into students (id, name) values( NULL, 'b'), (NULL, 'c'), (NULL, 'd');38-- 查找数据41-- 一个查询语句: select 列1, 列2, 列3 ... from 表名 可能条件42select id, name, class, chinese, english, math from students;43-- 只想知道: 每个人的人名,班级,语文成绩45select name, class, chinese from students;46-- *: 是个通配符, (只能用在查询的结果集中-> 每一个结果集都是一张临时表)48select * from students;49-- 删除数据52-- delete from 表名 可能的条件53delete from students; -- 没有加任何条件, 代表删除这个表的所有数据54-- 修改数据57-- update 表名 set 列=值, ... 可能的条件58update students set class='一班', name='zs' ; -- 没有条件, 修改了表所有数据59delete from students;62select * from students;64INSERT INTO students (id, name, class, chinese, english, math) VALUES (1, '武松', '一班', 70, 90, 60);67INSERT INTO students VALUES (2, '林冲', '一班', 70, 90, 90);68INSERT INTO students VALUES (3, '松江', '一班', 90, 90, 20);69INSERT INTO students VALUES (4, '贾琏', '二班', 60, 60, 60);70INSERT INTO students VALUES (5, '贾宝玉', '二班', 95, 80, 5);71INSERT INTO students VALUES (6, '贾环', '二班', 25, 25, 5);72INSERT INTO students VALUES (7, '曹操', '三班', 90, 90, 90);73INSERT INTO students VALUES (8, '曹丕', '三班', 90, 80, 80);74INSERT INTO students VALUES (9, '曹植', '三班', 98, 90, 80);75INSERT INTO students VALUES (10, '刘备', '三班', 95, 90, 80);76INSERT INTO students VALUES (11, '诸葛亮', '三班', 98, 95, 95);77INSERT INTO students VALUES (12, '孙权', '三班', 80, 90, 80);78INSERT INTO students (id) VALUES (13);79select * from students;82--84update students set name = "宋江" where id = 3;85update students set name = "宋江" where name = '松江';86-- 算数运算符可以配合where条件一起使用88-- 算数运算符也可以使用在查询结果(结果集)中89-- : 获取所有人的人名, 每个人总成绩91select name, english+math+chinese from students92-- 查询: 知道谁总成绩不及格94select * from students;95select * from students where english+math+chinese <= 180;97-- 数学老师: 数学和语文的偏科情况100select name , chinese - math from students;101select name , chinese-math from students where chinese-math >= 10;103-- 绩点: 100-60 /10105select name, (chinese-60)/10 + (math-60)/10 + (english-60)/10 from students107select name, (chinese-60)/10 + (math-60)/10 + (english-60)/10 from students where (chinese-60)/10 + (math-60)/10 + (english-60)/10 > 0109select name, (chinese-60)/10 + (math-60)/10 + (english-60)/10 from students where (chinese-60)/10 + (math-60)/10 + (english-60)/10 > 0111-- 比较运算符: 只能用在条件中, 不能用在结果中114select * from students;115-- 数学成绩为90有谁117select * from students where math = 90;118select * from students where math <=> 90;119-- 数学成绩为null121select * from students where math = null;122select * from students where math <=> null;123-- 查询数学成绩不是90的同学125select * from students where math != 90;126-- 数学成绩不及格的同学128select * from students where math < 60;129-- 数学成绩大于90分的同学131select * from students where math > 90;132-- 逻辑运算:134-- 判断某一个内容是否是null135-- 查询: 数学成绩为null的同学的信息136select * from students where math is null;137-- 查询: 数学成绩不是null的同学的信息139select * from students where math is not null;140-- 查询: 数学成绩在60 -90之间143select * from students where math between 60 and 90;144-- 查询: 数学成绩 5分 或者 95146select * from students where math in (5, 95);147-- 查询数学成绩不是 5分 也不是 95149select * from students where math not in (5, 95);150-- like用来做字符串的模糊查询的153-- 查询姓名为曹操的那个人的信息155select * from students where name = "曹操";156select * from students where name like "曹操";157-- 查询姓曹的人159select * from students where name like "曹%";160update students set name="曹阿瞒" where id = 7;162-- 查询姓曹的人: 要求这个人的人名是两个字164select * from students where name like "曹_";165-- 查询姓曹的人: 要求这个人的人名是三个字167select * from students where name like "曹__";168-- 查询数学成绩要么是5分 要么是95171select * from students where math=5 or math=95;172select * from students where math=5 || math=95;173-- 查询语文成绩大于等于90 并且 数学成绩也大于等于90175select * from students where math>=90 and chinese >=90;176select * from students where math>=90 && chinese >=90;177-- 使用`DISTINCT`对数据表中`一个或多个字段`重复的数据进行过滤,179-- 重复的数据只返回其`一条`数据给用户.180-- 数学老师: 想知道当前所有同学中, 有哪些数学分值183-- distinct math : 对math去重184select distinct math from students185-- 班主任: 有哪些类型的组合: 数学 和 语文成绩187select distinct chinese, math from students188-- `ORDER BY`对查询数据结果集进行排序.191-- ASC: 升序排序.192-- DESC: 降序排序.193-- 班级所有的人, 数学成绩, 按照数学成绩排序195select name, math from students;196select name, math from students order by math;197select name, math from students order by math desc;198-- 班级所有的人, 数学成绩, 语文成绩, 优先按照数学成绩从高到低,201-- 如果数学成绩一样, 按照语文从高到低202select name, math, chinese from students203select name, math, chinese from students order by math desc;204select name, math, chinese from students order by math desc, chinese desc;205-- 获得所有同学, 数学成绩前3名的同学: 姓名, 数学成绩208select name, math from students order by math desc;209-- LIMIT 记录数目: 从第一条开始, 限定记录数目211-- LIMIT 初始位置,记录数目: 从起始位置开始, 限定记录数目212-- LIMIT 记录数目 OFFSET 初始位置: 从起始位置开始, 限定记录数目213select name, math from students order by math desc limit 3;215select name, math from students order by math desc limit 0, 3;216select name, math from students order by math desc limit 3 offset 0;217-- 字符串可以排序吗?
7月3号是sql
xxxxxxxxxx4891SELECT * FROM `students`2-- 按照数学成绩从高到低显示所有人的信息4SELECT * FROM `students` order by math desc;5-- 按照姓名排序 显示所有人的信息7SELECT * FROM `students` order by name;8create databases `order`;10-- `AS` 关键字用来为表和字段指定别名.13-- 查询学生姓名, 和总成绩15select name as b, chinese+math+english as a from students;16select name as b, chinese+math+english as a from students ;18-- 聚合函数:21-- 聚合函数一般经常和分组(group by)一起使用22-- 聚合函数, 也可以单独使用23-- 聚合函数单独使用:26-- 所有人的人名28select name from students;29-- 获得一班所有人的人名30select name from students where class="一班";31-- 想知道一班有几个人33-- count(): 计数34select count(name) from students where class="一班";35select id from students where class="一班";36select count(id) from students where class="一班";37select count(*) from students where class="一班";38-- 统计一班同学所有人的数学的总成绩, 以及一班有几个人41-- sum , count42select name, math from students where class = "一班";43select count(name), sum(math) from students where class = "一班";45-- 统计一班同学平均数学成绩48select sum(math)/count(name) from students where class = "一班";49-- avg: 平均51select math from students where class = "一班";52select avg(math) from students where class = "一班";53-- 获得一班的最大的数学成绩 和 最小的数学成绩55select max(math), min(math) from students where class = "一班";56-- 聚合函数:60-- 聚合函数一般经常和分组(group by)一起使用61-- 有一些数据, 对数据按照指定条件进行分组,62-- 分完组之后, 通过对每一组数据进行聚合得到聚合结果63select * from students;65select68class, sum(math) as sum_math, sum(chinese) as sum_chinese69from students70group by class;71-- 特别想根据班级分组, 并且想获得每一个组组内有几个人, 以及人名,74-- group_concat (对分组的, 非分组列, 通过逗号连接一起显示 )75select class, count(name) from students group by class;77select class, count(name), group_concat(name) from students group by class;78-- 获得每个班级, 人数, 以及班级的平均数学成绩81select class , count(id), avg(math) from students group by class;82-- 获得每个班级, 人数, 以及班级的平均数学成绩, 只保留平均数学成绩及格班级信息85select86class , count(id), avg(math)87from students88group by class89where avg(math) >=60; -- 会报错: 不允许先分组再where; 要先where再分组90select93class , count(id), avg(math)94from students95where avg(math) >=6096group by class; -- 报错: 还没有分组的时候, 想在条件中使用聚合信息97-- having: 解决在group by之后不能使用where的问题101-- 专门给group by使用, 在分组之后, 使用having对分组相关信息进行过滤102select103class , count(id), avg(math)104from students105group by class106having avg(math) >=60;107-- 查询学生信息, 要求统计每个班级中数学成绩及格的同学的平均成绩110-- 知道这些及格同学的班级的平均数学成绩, 那个班级是第2名111select113class, avg(math) as avg_math114from students115where math >= 60116group by class117order by avg_math desc118limit 1, 1119--122drop table students, user1, user2, user3;123--125-- 班级127CREATE TABLE `class` (128`id` int(11) NOT NULL,129`class_name` varchar(10) ,130PRIMARY KEY (`id`)131);132-- 成绩133CREATE TABLE `score` (134`id` int(11) NOT NULL AUTO_INCREMENT,135`student_id` int(11) ,136`class_id` int(11),137`chinese` float ,138`english` float ,139`math` float ,140PRIMARY KEY (`id`)141);142-- 学生信息143CREATE TABLE `student` (144`id` int(11) NOT NULL,145`student_name` varchar(20),146`nick_name` varchar(20) ,147`mobile` varchar(20) ,148`era` varchar(20),149`motto` varchar(30),150PRIMARY KEY (`id`)151);152-- 剧本153CREATE TABLE `script` (154`id` int(11) NOT NULL,155`play_name` varchar(20),156`play_ location` varchar(20) ,157PRIMARY KEY (`id`)158);159-- 演出表160CREATE TABLE `show` (161`id` int(11) NOT NULL,162`student_id` int(11),163`script_id` int(11),164PRIMARY KEY (`id`)165);166-- ----------------------------168INSERT INTO `class` VALUES (1, '一班');169INSERT INTO `class` VALUES (2, '二班');170INSERT INTO `class` VALUES (3, '三班');171INSERT INTO `class` VALUES (4, '四班');172INSERT INTO `class` VALUES (5, '五班');173-- ----------------------------174INSERT INTO `score` VALUES (1, 1, 1, 70, 90, 60);175INSERT INTO `score` VALUES (2, 2, 1, 70, 90, 90);176INSERT INTO `score` VALUES (3, 3, 1, 90, 90, 20);177INSERT INTO `score` VALUES (4, 4, 2, 60, 60, 60);178INSERT INTO `score` VALUES (5, 5, 2, 95, 80, 5);179INSERT INTO `score` VALUES (6, 6, 2, 25, 25, 5);180INSERT INTO `score` VALUES (7, 7, 3, 90, 90, 90);181INSERT INTO `score` VALUES (8, 8, 3, 90, 80, 80);182INSERT INTO `score` VALUES (9, 9, 3, 98, 90, 80);183INSERT INTO `score` VALUES (10, 10, 3, 95, 90, 80);184INSERT INTO `score` VALUES (11, 11, 3, 98, 95, 95);185INSERT INTO `score` VALUES (12, 12, 3, 80, 90, 80);186-- ----------------------------187INSERT INTO `script` VALUES (1, '三打祝家庄', '祝家庄');188INSERT INTO `script` VALUES (2, '梁山聚义', '梁山');189INSERT INTO `script` VALUES (3, '壮士落幕', '六和寺');190INSERT INTO `script` VALUES (4, '赤壁之战', '赤壁');191INSERT INTO `script` VALUES (5, '七步诗事件', '洛阳');192INSERT INTO `script` VALUES (6, '白帝城托孤', '白帝城');193INSERT INTO `script` VALUES (7, '煮酒论英雄', '许昌');194-- ----------------------------195INSERT INTO `show` VALUES (1, 1, 1);196INSERT INTO `show` VALUES (2, 2, 1);197INSERT INTO `show` VALUES (3, 3, 1);198INSERT INTO `show` VALUES (4, 1, 2);199INSERT INTO `show` VALUES (5, 2, 2);200INSERT INTO `show` VALUES (6, 3, 2);201INSERT INTO `show` VALUES (7, 1, 3);202INSERT INTO `show` VALUES (8, 2, 3);203INSERT INTO `show` VALUES (9, 7, 4);204INSERT INTO `show` VALUES (10, 10, 4);205INSERT INTO `show` VALUES (11, 11, 4);206INSERT INTO `show` VALUES (12, 12, 4);207INSERT INTO `show` VALUES (13, 8, 5);208INSERT INTO `show` VALUES (14, 9, 5);209INSERT INTO `show` VALUES (15, 11, 6);210INSERT INTO `show` VALUES (16, 12, 6);211INSERT INTO `show` VALUES (17, 7, 7);212INSERT INTO `show` VALUES (18, 11, 7);213-- ----------------------------214INSERT INTO `student` VALUES (1, '武松', '行者', '13440996665', '宋朝', '别胡说!难道不付你钱!再筛三碗来!');215INSERT INTO `student` VALUES (2, '林冲', '豹子头', '17383945041', '宋朝', '无');216INSERT INTO `student` VALUES (3, '宋江', '及时雨', '15671722818', '宋朝', '他日若遂凌云志,敢笑黄巢不丈夫');217INSERT INTO `student` VALUES (4, '贾琏', '琏二爷', '19931477852', '清朝', '无');218INSERT INTO `student` VALUES (5, '贾宝玉', '怡红公子', '13456229050', '清朝', '我要这玉又何用');219INSERT INTO `student` VALUES (6, '贾环', '孽障', '18900141462', '清朝', '无');220INSERT INTO `student` VALUES (7, '曹操', '阿满', '17273083171', '三国', '宁我负人,毋人负我');221INSERT INTO `student` VALUES (8, '曹丕', '子桓', '17180453185', '三国', '无');222INSERT INTO `student` VALUES (9, '曹植', '陈思王', '19818008917', '三国', '无');223INSERT INTO `student` VALUES (10, '孙权', '孙十万', '15638204123', '三国', '无');224INSERT INTO `student` VALUES (11, '刘备', '刘皇叔', '15638204378', '三国', '惟贤惟德,能服行人');225INSERT INTO `student` VALUES (12, '诸葛亮', '诸葛武侯,卧龙', '15119511196', '三国', '非淡泊无以明志,非宁静无以致远');226select * from class;229select * from score;230select * from student;231select * from `show`;232select * from script;233-- 表和表之间的关系236-- 多张表之间怎么做查询得到汇总信息238-- 装备表240CREATE TABLE `equip` (241`id` int(11) NOT NULL PRIMARY KEY,242`student_id` int(11) NULL DEFAULT NULL,243`equip_name` varchar(255) NULL DEFAULT NULL244) ;245INSERT INTO `equip` VALUES (1, 1, '行者套账');247INSERT INTO `equip` VALUES (2, 2, '丈八蛇矛');248INSERT INTO `equip` VALUES (3, 5, '通灵宝玉');249INSERT INTO `equip` VALUES (4, 7, '七星刀');250INSERT INTO `equip` VALUES (5, 7, '绝影马');251INSERT INTO `equip` VALUES (6, 7, '爪黄飞电马');252INSERT INTO `equip` VALUES (7, 7, '倚天剑');253INSERT INTO `equip` VALUES (8, 7, '青釭剑');254INSERT INTO `equip` VALUES (9, 11, '的卢马');255INSERT INTO `equip` VALUES (10, 11, '双股剑');256select * from class;260select * from score;261select * from student;262select * from `show`;263select * from script;264select * from equip;265-- 多张表之间怎么做查询得到汇总信息268-- 获得一班同学的姓名, 以及对应装备269select271c.class_name, st.student_name, e.equip_name272from class c273inner join score sc on c.id = sc.class_id274inner join student st on st.id = sc.student_id275inner join equip e on e.student_id = st.id276where c.class_name = '一班'277-- 表和表的连接问题280-- 交叉连接282select *283from student284cross join equip285where student.id = student_id286select *288from student289cross join equip290where student.id = equip.student_id291select *294from student as st295cross join equip as eq296where st.id = eq.student_id297select *299from student st300cross join equip eq301where st.id = eq.student_id302-- 自然连接306select *307from class308natural join equip309--311select * from student312-- 内连接315-- select 结果 from 表1 inner join 表2 on 表1和表2的链接条件316-- 根据链接条件, 保留最终两个表按照条件能匹配的数据317-- 获得每个人的和每个人的装备319select320*321from student st322inner join equip e on st.id = e.student_id323-- 隐式的内连接: 不建议这么写326select327*328from student st, equip e329where st.id = e.student_id330-- 外连接: 左外链接, 右外连接333-- SELECT 结果 FROM <表1> LEFT OUTER JOIN <表2> on 表1和表2的链接条件335-- SELECT 结果 FROM <表1> RIGHT OUTER JOIN <表2> on 表1和表2的链接条件336-- 和inner join的区别: inner join保留最终两个表按照条件能匹配的数据337-- 外连接中: 会以主表为核心, 保留所有主表的数据,338-- 在结果集中, 把副表中没有对应数据匹配的内容 填null339-- 主表, 副表341select343*344from student st345left outer join equip e on st.id = e.student_id346order by student_id desc347select350*351from student st352right outer join equip e on st.id = e.student_id353select356*357from student st358right outer join equip e on st.id = e.student_id359where student_name is not null360-- outer省略362select363*364from student st365right join equip e on st.id = e.student_id366-- 自连接: 自己和自己做链接查询371-- 查询数学成绩低于林冲的数学成绩的人的信息373select374t1.*375from score t1,score t2376where t2.id = 2 and t1.chinese < t2.chinese377select379*380from score sc381where sc.chinese < 林冲的语文成绩382select chinese from score where id=2384select387*388from score sc389where sc.chinese < ( select chinese from score where id=2 )390-- 子查询也叫嵌套查询.( 在某个操作中(删除/修改/查找), 用到了另外一个查询的结果. )393-- 是指在WHERE子句或FROM子句中又嵌入SELECT查询语句.394-- 把所有语文成绩小于林冲的语文成绩, 语文改成0分397update score set chinese = 0398where chinese < 林冲的语文成绩399update score set chinese = 0402where chinese < (403select chinese from score where id=2404)405select * from ( select chinese from score where id=2 ) as temp408update score set chinese = 0410where chinese < (411select * from ( select chinese from score where id=2 ) as temp412)413-- `联合查询`合并两条查询语句的查询结果.416-- `联合查询`去掉两条查询语句中的重复数据行,然后返合并后没有重复数据行的查询结果。417select * from score where chinese >= 90419union420select * from score where math >= 90;421select * from score where chinese >= 90 or math >= 90;423select * from score;426select * from student;427-- 获得每个班级中, 数学成绩最高的那个人的: 班级,姓名, 数学成绩430select432c.class_name, st.student_name, sc.math433from class c434inner join score sc on c.id = sc.class_id435inner join student st on sc.student_id = st.id436-- 有没有办法, 直接获得每个班级的最高数学成绩439select440sc2.class_id, max(sc2.math)441from score sc2442group by sc2.class_id443select447c.class_name, st.student_name, sc.math448from class c449inner join score sc on c.id = sc.class_id450inner join student st on sc.student_id = st.id451inner join (452select453sc2.class_id, max(sc2.math) as max_math454from score sc2455group by sc2.class_id456)temp on temp.class_id = sc.class_id and temp.max_math = sc.math457--459select460c.class_name, st.student_name, sc.math461from class c462inner join score sc on c.id = sc.class_id463inner join student st on sc.student_id = st.id464where sc.math = 班级的最大数学成绩465select469sc2.math470from score sc2471where sc2.class_id = 班级id472order by sc2.math desc473limit 1474--477select478c.class_name, st.student_name, sc.math479from class c480inner join score sc on c.id = sc.class_id481inner join student st on sc.student_id = st.id482where sc.math = (483select484sc2.math485from score sc2486where sc2.class_id = sc.class_id487order by sc2.math desc488limit 1489)